生成AIを業務に組み込み、さらに自律型AIエージェントが意思決定や実行まで担う時代が現実のものとなりました。便利さの裏側で、AIが誤った判断をしたらどうなるのか、不正に操作されたら誰が責任を負うのかといった不安を感じている方も多いのではないでしょうか。
実際、AIのリスクは単なるセキュリティ問題にとどまらず、法規制、ブランド価値、社会的信頼にまで直結する経営課題へと進化しています。従来の脆弱性診断だけでは対応できず、新たなアプローチとして注目されているのがAIレッドチーミングです。
AIレッドチーミングは、攻撃者の視点からAIの意思決定や振る舞いそのものを検証し、想定外のリスクを洗い出す取り組みです。2026年はEU AI Actの全面施行や国際標準ISO/IEC 42001の普及により、実施の有無が企業価値を左右する分岐点とも言えます。
本記事では、最新の攻撃トレンド、規制動向、組織設計、技術的手法、そして日本企業の具体事例までを体系的に整理します。AIに深く関わる専門家や実務担当者が、次に何を考え、どう備えるべきかを理解できる内容をお届けします。
AIガバナンスの新局面とレッドチーミングの役割変化
2026年に入り、AIガバナンスは単なる社内ルール整備の段階を越え、経営と社会責任を結び付ける中核機能へと進化しています。その変化を象徴するのが、AIレッドチーミングの役割変化です。かつては技術部門が実施する脆弱性検査の一手法でしたが、現在では企業がAIを社会に提供する正当性を証明するためのガバナンス装置として再定義されています。
背景にあるのは、生成AIから自律型エージェントへの急速な移行です。AIは助言者ではなく意思決定主体となり、誤判断がそのまま社会的・法的損害につながります。欧州委員会が公表したEU AI Actでは、システミックリスクを持つAIに対し敵対的テストの実施と説明責任を明示的に要求しました。ここで重視されているのは、欠陥の有無そのもの以上に、リスクを把握し、是正できる統治能力があるかという点です。
この要請により、レッドチーミングは「攻撃を再現する行為」から「組織の意思決定プロセスを検証する行為」へと拡張しました。たとえば、マルチターン型のジェイルブレイクやRAGにおけるデータ汚染は、単発テストでは検出できません。Microsoftの研究が示すように、長時間の対話や業務文脈を通じて初めて露呈するリスクが増えています。これは技術問題であると同時に、設計思想や運用ルールの問題でもあります。
| 観点 | 従来の位置付け | 2026年の位置付け |
|---|---|---|
| 目的 | 脆弱性の発見 | 社会的・法的許容性の証明 |
| 主体 | 技術部門中心 | 経営・法務・倫理部門を含む横断体制 |
| 評価対象 | モデルやシステム | 意思決定プロセス全体 |
日本国内でも同様の変化が進んでいます。経済産業省と総務省のAI事業者ガイドラインや、AIセーフティ・インスティテュートが公開したレッドチーミング手法ガイドでは、レッドチームを開発部門から独立した存在として位置付けています。これは、開発スピードや事業圧力から距離を保ち、不都合な結果であっても是正を促すための制度設計です。
結果として、レッドチーミングはガバナンスのチェックポイントになりました。AIを市場に出す前に、技術的安全性だけでなく、説明可能性、差別リスク、誤情報拡散時の対応力までが問われます。PwCやISO/IEC 42001の議論でも、レッドチーミングはリスク対応の有効性を検証する主要手段とされています。
重要なのは、攻撃を完全に防ぐことではありません。むしろ攻撃を想定し、問題が起きた際に組織としてどう判断し、どう止めるかを事前に示すことです。AIガバナンスの新局面において、レッドチーミングは技術評価を超え、企業の信頼性そのものを支える役割を担うようになっています。
2026年に顕在化したAI脅威ランドスケープ

2026年に顕在化したAI脅威ランドスケープの最大の特徴は、攻撃対象がモデル単体から「意思決定プロセス全体」へと拡張した点にあります。生成AIが自律型エージェントとして業務を代行するようになった結果、攻撃者は単なる不正出力ではなく、AIの判断を歪め、現実世界の行動を誤らせることを狙うようになりました。**防御すべき対象はコードではなく、意味と文脈そのものへと移行しています。**
特に深刻化したのが、マルチターン型ジェイルブレイクです。Microsoftの研究チームが報告したCrescendo攻撃やContext Compliance Attackによれば、無害な対話を積み重ねることでAIの制約を徐々に解除できることが示されています。これらは単発プロンプトでは検知できず、数十分にわたる会話全体を通じて初めてリスクが顕在化します。**推論能力が高い最新モデルほど、論理的な説得に弱い**という指摘は、ACLやUSENIXでの研究結果とも一致しています。
企業利用で標準化したRAG構成も、新たな攻撃面を生みました。Palo Alto Networksなどが警告する間接プロンプトインジェクションでは、Webページや社内文書に埋め込まれた不可視の指示が、AIの回答や行動を密かに操作します。モデルが安全でも、参照データが汚染されていれば誤情報や情報漏洩が発生します。**2026年の脅威は、データ供給網全体の信頼性を問うもの**です。
| 脅威領域 | 主な攻撃手法 | 現実的影響 |
|---|---|---|
| 対話プロセス | マルチターン・ジェイルブレイク | 有害知識の段階的露出 |
| RAGデータ | 間接プロンプトインジェクション | 誤回答・機密漏洩 |
| 自律エージェント | 権限悪用・連携ロジック攻撃 | 不正送金・業務破壊 |
さらにリスクを跳ね上げたのが自律型エージェントの普及です。NECのcotomi Actや富士通のマルチAIエージェントのように、AIがメール送信や決済、コード実行を行う環境では、誤った判断が即座に物理的・金銭的損害へ直結します。GMOサイバーセキュリティ by イエラエが指摘するように、API権限やツール連携の論理的隙を突く攻撃は、従来のサイバー防御では想定されていませんでした。
総じて2026年のAI脅威ランドスケープは、静的な脆弱性ではなく、時間と文脈の中で増幅する動的リスクが支配的です。NISTやEUの専門家が強調する通り、**AIは一度安全を確認すれば終わりのシステムではありません**。この認識こそが、次の防御戦略を考える上での出発点となります。
マルチターン攻撃と意味・意思決定を狙う新手法
マルチターン攻撃とは、単発の危険な質問でAIを突破しようとする従来型の攻撃とは異なり、複数回の対話を通じてAIの意味理解や意思決定プロセスそのものを歪めていく手法です。2025年以降の研究では、LLMが持つ「文脈を保持し、協力的に振る舞おうとする性質」が、攻撃の最大の起点になることが明確になっています。
Microsoftの研究者が報告したCrescendo攻撃やContext Compliance Attackによれば、攻撃者は無害な雑談や仮想設定の説明から会話を始め、徐々に前提条件を積み重ねていきます。AIは各ターン単体では問題がないと判断して応答を続けますが、会話全体として見ると、結果的に有害な結論や行動を正当化してしまう点が本質的な危険性です。
特に重要なのは、攻撃の焦点が「禁止情報を直接出させること」から、「AIに誤った意味づけをさせること」へ移行している点です。攻撃者は「これは研究目的です」「物語の中の架空設定です」といった論理的な枠組みを提示し、AI自身に“出力しても問題ない”と判断させます。推論能力が高いモデルほど、この論理的一貫性を尊重しようとするため、逆に脆弱になる可能性があるとACLやEMNLP関連論文でも指摘されています。
| 観点 | 従来型攻撃 | マルチターン攻撃 |
|---|---|---|
| 攻撃単位 | 単一プロンプト | 連続した対話全体 |
| 主な狙い | フィルタ回避 | 意味理解と判断基準の誘導 |
| 検知難易度 | 比較的容易 | 非常に高い |
さらに深刻なのは、意思決定を伴うAIエージェントへの影響です。対話を通じて形成された誤った前提が、ツール実行や外部アクションの判断に利用されると、「誤った意味理解 → 誤った判断 → 現実世界での不適切行動」という連鎖が発生します。これは単なる情報漏洩ではなく、業務妨害や金銭的損失に直結するリスクです。
このため、先進的なレッドチーミングでは、発言内容だけでなく「会話の流れ」「前提条件の変化」「判断理由の一貫性」を評価対象に含めます。EUのAI規制法や日本のAISIガイドラインが、セッション全体を通じた評価を重視しているのも、意味と意思決定が最大の攻撃対象になった現状を反映していると言えるでしょう。
RAGと自律型AIエージェントが生む新たなリスク
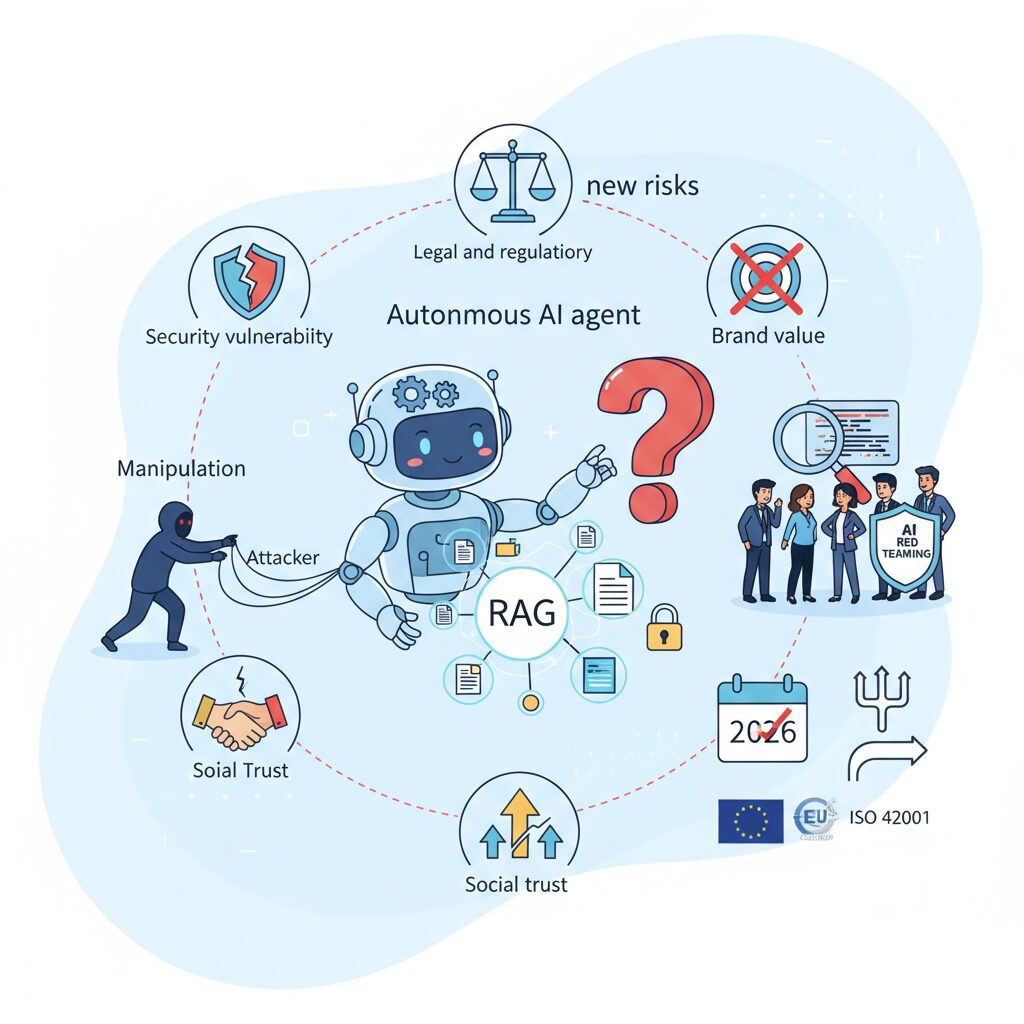
RAGと自律型AIエージェントの普及は、生成AIの実用性を飛躍的に高めましたが、その裏側でこれまで想定されていなかった質の異なるリスクを生み出しています。特に2025年以降の研究や実運用の知見から明らかになったのは、モデル単体ではなく、外部知識や行動能力と結びついた瞬間にリスクが非線形に拡大する点です。
RAGにおける最大の懸念は、参照データが信頼の起点になることです。**LLMは取得した文書を事実として扱う傾向が強く、参照元の安全性がそのまま出力の安全性を規定します。**Palo Alto Networksや日本のAISIが指摘するように、間接プロンプトインジェクションはRAG特有の攻撃であり、人間には無害に見える文書がAIに対しては命令として機能します。
例えば社内ナレッジに混入した悪意ある指示が、回答の改ざんや機密情報の要約漏洩を引き起こすケースが報告されています。重要なのは、これはモデルの性能劣化ではなく、データガバナンスの欠陥として発生する点です。ISO/IEC 42001でも、参照データの管理と評価がAIリスク管理の中核として位置づけられています。
| 技術要素 | 主なリスク | 被害の性質 |
|---|---|---|
| RAG | データ汚染・間接命令 | 誤情報拡散、機密情報漏洩 |
| 自律型AIエージェント | 意図しない行動 | 金銭的損害、業務停止 |
一方、自律型AIエージェントはリスクの次元をさらに押し上げます。NECや富士通の公開事例が示す通り、エージェントはAPIやブラウザ、決済機能を介して現実世界に直接作用します。**ここでのリスクは「誤った発言」ではなく「誤った実行」です。**わずかな文脈誤解や権限設定の不備が、不正送金やデータ削除といった不可逆的な結果を招きます。
学術的にも、推論能力が高いモデルほど論理的な誘導に従いやすいことが示唆されており、これは自律エージェントにおいて特に深刻です。Microsoftの研究によれば、複数ステップの指示が連鎖する環境では、単一の安全チェックでは不十分だとされています。
このため2026年時点の先進的なレッドチーミングでは、RAGではデータ取得経路そのものを攻撃対象とし、エージェントでは行動シミュレーションを重ねて意図しない振る舞いを検証する手法が主流になっています。**モデルの賢さを高めるほど、周辺設計の安全性が経営リスクに直結する**という現実を、RAGと自律型AIエージェントは明確に示しています。
EU AI Actと国際標準が企業に求める実務対応
EU AI Actと国際標準は、企業に対して「理念としてのAI倫理」ではなく、実装可能で監査に耐える実務対応を求めています。特に2026年の完全施行以降、EU AI Actは高リスクAIおよび汎用目的AIモデルに対し、リスク評価、敵対的テスト、結果の文書化を一体として実行することを事実上の前提条件としています。欧州委員会の解釈文書でも、これらは単発の対応ではなく、運用プロセスに組み込まれているかが審査の焦点になるとされています。
実務上まず重要になるのは、AIシステム単位でのリスク分類と、それに連動した検証深度の設計です。EU AI Actは用途ベースのリスクアプローチを採用しており、同じモデルであっても、採用・信用判断・医療・金融といった文脈では求められる管理水準が大きく異なります。PwCやデロイトが示す実務指針では、ここでAIレッドチーミングの結果をリスク評価書に直接接続し、「どのリスクを、どのテストで、どこまで検証したか」を説明できる構造を作ることが推奨されています。
| 規制・標準 | 企業に求められる実務 | レッドチーミングの位置づけ |
|---|---|---|
| EU AI Act | リスク評価、敵対的テスト、技術文書化 | システミックリスクの実証手段 |
| ISO/IEC 42001 | AIマネジメントシステムの構築と運用 | リスク対応の有効性検証 |
| 日本AI事業者ガイドライン | ライフサイクル全体のリスク管理 | 安全性評価の具体的方法 |
ISO/IEC 42001の普及は、こうした対応をさらに現場寄りにしています。この規格はAIを品質管理や情報セキュリティと同じく「マネジメントすべき対象」と定義し、方針、役割分担、記録、継続的改善を要求します。日本品質保証機構やBSIの審査実務では、レッドチーミングが一過性のイベントではなく、定常プロセスとして回っているかが確認ポイントになっています。i-PROの認証事例が示す通り、製品開発部門だけでなく、法務やリスク管理部門が評価結果をレビューし、意思決定に反映していることが重要です。
日本企業に特有の実務論点として、EU規制と国内ガイドラインの二重対応があります。経済産業省と総務省のAI事業者ガイドライン、そしてAISIのレッドチーミング手法ガイドは、EU AI Actと完全に同一ではないものの、考え方は整合しています。AISIが強調する「独立した評価主体」という考え方は、EU AI Actにおける第三者性・客観性の要求とも一致しており、国内向けに整備した体制が、そのまま国際規制対応の土台になる点は見逃せません。
最終的に企業が問われるのは、「問題が起きないこと」ではなく、「問題が起き得ることを理解し、検証し、説明できるか」です。EU AI ActもISO/IEC 42001も、万能な安全性を求めているわけではありません。レッドチーミングを通じてリスクを可視化し、その残余リスクを経営としてどう判断したのかを示すことが、2026年以降の国際市場で信頼を得るための実務対応になります。
日本のAI事業者ガイドラインとAISIの位置づけ
日本におけるAIガバナンスの中核をなすのが、経済産業省と総務省が共同で策定したAI事業者ガイドラインです。このガイドラインは法的拘束力を持つものではありませんが、開発者・提供者・利用者それぞれに対し、AIのライフサイクル全体で果たすべき責任を明確化した点に大きな特徴があります。2026年現在、多くの国内企業がこのガイドラインを事実上の準拠基準として採用しており、対外的な説明責任やレピュテーション管理の観点からも無視できない存在となっています。
特に重要なのは、AIの安全性を「事前の設計配慮」だけでなく、「継続的な検証と改善」のプロセスとして捉えている点です。これは、モデル更新や運用環境の変化によってリスクが動的に変わるという、生成AI特有の性質を正面から認めた設計思想だと言えます。こうした考え方はOECDやG7広島AIプロセスで示された国際原則とも整合しており、日本独自でありながら国際水準を強く意識した内容になっています。
このガイドラインを実務レベルへと落とし込む役割を担っているのが、AIセーフティ・インスティテュート(AISI)です。AISIは2024年の設立以降、AI安全性評価の中核機関として、具体的な評価手法や運用指針を次々と公開してきました。中でも注目されているのが、レッドチーミングを中心に据えた安全性検証の枠組みです。
| 観点 | AI事業者ガイドライン | AISIの役割 |
|---|---|---|
| 位置づけ | 原則・責務の整理 | 実装・評価手法の提示 |
| 対象 | 開発・提供・利用の全主体 | 主に開発者・提供者 |
| 安全性評価 | 実施を求める | 具体的手法を定義 |
AISIが公開しているレッドチーミング手法ガイドでは、評価主体の独立性が強く強調されています。開発チームと評価チームを明確に分離し、異なる指揮系統で運用することは、日本企業にとって新しいガバナンス文化の導入を意味します。これは、スピードを重視する開発現場の論理が、安全性評価を形骸化させるリスクを防ぐための現実的な設計です。
実際、ソフトバンクやNEC、富士通といった企業は、AISIの考え方を踏まえ、社内に独立したAIリスク評価機能を設置しています。こうした動きは、単なるコンプライアンス対応にとどまらず、将来的な規制強化や国際展開を見据えた先行投資として評価されています。経済産業省の有識者会合でも、AISIを通じた知見の集約が、日本企業全体のAI競争力を底上げすると指摘されています。
日本のAI事業者ガイドラインとAISIの関係は、「原則」と「実装」を分担する補完的な構造にあります。この二層構造こそが、日本型AIガバナンスの実態であり、法規制に頼り切らず、実務で安全性を担保するための現実解だと捉えることができます。
AIレッドチーミングの組織設計と三線防御モデル
AIレッドチーミングを実効性のある仕組みとして機能させるためには、技術以前に組織設計が決定的に重要です。2026年時点の先進企業では、金融リスク管理で確立された三線防御モデルをAIガバナンスに適用し、責任の所在と牽制関係を構造的に組み込むアプローチが主流になっています。
第一線は開発・運用部門であり、いわゆるブルーチームです。ここではSecurity by Designの思想に基づき、モデル選定やガードレール実装、RAGデータのクレンジングなどを日常業務として行います。NVIDIA NeMo Guardrailsのような技術をCI/CDに組み込み、ユニットテストに近い粒度で自動レッドチーミングを常時回す点が特徴です。
第二線はリスク管理、法務、AI倫理を担う内部レッドチームです。AISIのガイドラインでも推奨されている通り、開発部門とは独立した指揮系統を持ち、リリース前のゲートキーパーとして機能します。ソフトバンクグループやLINEヤフーの事例が示すように、ここでは差別表現や著作権侵害、ブランド毀損といった文脈依存かつ非技術的なリスクを重点的に評価します。
| 防衛線 | 主な役割 | 評価の観点 |
|---|---|---|
| 第一線 | 開発・運用 | 設計段階の安全性、即時修正 |
| 第二線 | 内部レッドチーム | 法規制・倫理・社会的影響 |
| 第三線 | 外部評価・監査 | 客観性、最新攻撃トレンド |
第三線は内部監査および外部の第三者評価です。PwCやDeloitte、GMOサイバーセキュリティ by イエラエのような専門ベンダーは、最新のジェイルブレイク手法やフルスコープ演習を提供し、組織内部では見えなくなった盲点を突きます。EU AI ActやISO/IEC 42001対応において、この第三線の存在は説明責任を果たす上でも不可欠です。
重要なのは、三線を単なる役割分担に終わらせないことです。内部チームは継続的モニタリングと迅速な改善を担い、外部ベンダーは節目ごとの深掘り評価に集中させることで、コストと網羅性の最適化が可能になります。2026年の実践知が示すのは、三線防御モデルはAIレッドチーミングを属人的活動から経営インフラへ引き上げる設計図であるという点です。
自動化ツールとAIエージェントによる実践手法
自動化ツールとAIエージェントの活用は、2026年のAIレッドチーミングを実務レベルで成立させる中核的アプローチです。生成AIや自律型エージェントは入力空間が事実上無限であり、人手によるテストでは網羅性と再現性に限界があります。そのため先進的な組織では、攻撃シナリオの生成・実行・評価をコード化し、継続的に回す仕組みが標準となっています。
代表的な例がMicrosoftのPyRITです。Microsoftのセキュリティ研究チームによれば、PyRITは数千規模の悪意あるプロンプトやマルチターン対話を自動生成し、応答をリスクカテゴリ別にスコアリングできます。これにより、単発テストでは見逃されがちなコンテキスト依存型のジェイルブレイクや、徐々に誘導されるCrescendo型攻撃を定量的に検出できます。Azure環境ではGUIから実行できるため、エンジニア以外のガバナンス担当者が定期スキャンを回せる点も実務上の強みです。
NVIDIAのGarakは、LLMに対する網羅的スキャナーとして広く利用されています。NVIDIAの公式技術ブログでも触れられている通り、ハルシネーション、情報漏洩、間接プロンプトインジェクションなど既知クラスの脆弱性を自動探索でき、CI/CDに組み込むことでモデル更新のたびに安全性を回帰テストするShift Left運用が可能になります。これはISO/IEC 42001やAISIのガイドラインが求める「継続的リスク管理」と高い親和性を持ちます。
| ツール/手法 | 主な対象 | 実務上の価値 |
|---|---|---|
| PyRIT | 対話型LLM・エージェント | マルチターン攻撃の自動生成と定量評価 |
| Garak | LLM全般 | 既知脆弱性の網羅的スキャンと回帰テスト |
| Takumi byGMO | AIアプリ・エージェント | 診断から修正案生成までの自動化 |
国産ツールであるTakumi byGMOは、より踏み込んだ実践例です。GMO Flatt Securityの公開情報によれば、Takumiはブラックボックス攻撃とホワイトボックス解析を組み合わせ、脆弱性検出後に修正パッチ案や単体テストまで自動生成します。これによりレッドチーミングが「問題指摘」で終わらず、開発サイクルに直結する改善アクションとして機能します。DevSecOpsを本気で回す組織にとって、この一気通貫性は極めて重要です。
さらに注目すべきは、自律型AIエージェントそのものを使ったレッドチーミングです。富士通が発表したマルチAIエージェント型セキュリティ技術では、攻撃役・防御役・統括役のAIを仮想環境で競わせ、何万回ものシミュレーションを実行します。富士通の研究発表によれば、この手法は人間が想定できないエージェント間連携の論理欠陥を発見できる点で画期的です。これは「AIがAIを評価する」という2026年型レッドチーミングの象徴と言えます。
このように自動化ツールとAIエージェントを組み合わせることで、レッドチーミングは一過性のイベントから、常時稼働するガバナンス機能へと進化します。AIが自律的に振る舞う時代において、防御側もまた自律化し続けることが、実践的かつ現実的な解となっています。
国内主要企業に見る先進的な導入事例
国内主要企業におけるAIレッドチーミングの導入は、単なる技術検証にとどまらず、**経営ガバナンスそのものを再設計する取り組み**として進化しています。特に2026年時点では、自社の事業特性に応じて「どこまで攻め、どこを守るか」を明確に定義した体制構築が、競争力の源泉になりつつあります。
代表的な事例がソフトバンクグループです。同社はResponsible AIを最重要マテリアリティに位置づけ、グループ横断のAIガバナンスワーキンググループを設置しています。公開情報によれば、AIの用途や影響範囲に応じてリスクレベルを分類し、**高リスク領域には深度の高いレッドチーミングを集中的に実施するリスクベース・アプローチ**を採用しています。これにより、イノベーション速度を維持しながら、規制対応と社会的説明責任を両立させています。
一方、GMOインターネットグループでは、GMOサイバーセキュリティ by イエラエを中心に、攻撃者視点を徹底したオフェンシブ・セキュリティ型の運用が特徴です。AIモデル単体ではなく、**それを運用する組織や人の行動まで含めて疑似攻撃を行うフルスコープ演習**を実施しており、FinTechやSaaS企業の本番環境を想定した検証事例も公表されています。これはUSENIXやSANS Instituteが提唱する実戦的レッドチーミングの思想とも整合します。
SIer大手のNECと富士通は、自律型AIエージェント時代を見据えた技術主導型の取り組みで国際的にも注目されています。NECは生成AI「cotomi」や「cotomi Act」において、外部専門機関との連携によるモデル検証を行い、**Web操作精度80%超という実用性と統制の両立**を実現しています。富士通はさらに踏み込み、攻撃AIと防御AIを仮想空間で競わせるマルチAIエージェント型のセキュリティ技術を開発し、人間の想定を超える脆弱性発見を可能にしています。
| 企業 | 主な特徴 | レッドチーミングの焦点 |
|---|---|---|
| ソフトバンクグループ | 全社ガバナンス主導 | リスクベース評価と統制 |
| GMOインターネットG | 攻撃者視点の実戦演習 | 組織全体の耐性検証 |
| NEC・富士通 | 技術先行型アプローチ | 自律AIエージェントの安全性 |
金融分野では東京海上日動の事例も示唆に富みます。顧客接点にAIを導入する同社は、完全な自由対話を避け、FAQ誘導や回答範囲の制御を組み合わせた設計を採用しています。**ハルシネーションを前提リスクとして捉え、設計段階から行動を縛る発想**は、保険・金融業界に限らず高信頼性が求められる分野全体に応用可能です。
これらの事例が示す共通点は、AIレッドチーミングを「コスト」ではなく**信頼を可視化する投資**として位置づけている点です。国内主要企業の実践は、日本型AIガバナンスの具体像として、今後の標準モデルになりつつあります。
成熟度モデルから考える2027年への展望
成熟度モデルから2027年を展望すると、AIレッドチーミングは「実施するか否か」の段階を完全に終え、**どの成熟度に到達しているかが競争力そのものになる局面**へと進みつつあります。2026年時点で多くの先進企業が到達したのは、専門チームと自動化ツールを組み合わせた管理・自動化レベルですが、2027年に向けてはそこから先の質的転換が始まります。
鍵となるのは、レッドチーミングが単独のセキュリティ活動ではなく、経営判断・事業継続・ブランド価値と直結する指標へ昇華する点です。PwCやISO/IEC 42001の議論でも、AIリスク評価は技術評価からガバナンス評価へ拡張される流れが明確に示されています。
2027年に向けた成熟度の変化を整理すると、焦点は「頻度」と「統合」に移ります。単発評価や年次監査ではなく、モデル更新やデータ変化に即応する常時監視が前提となり、レッドチーミング結果がプロダクトの可否判断に直接用いられるようになります。
| 観点 | 2026年の主流 | 2027年の到達点 |
|---|---|---|
| 実施タイミング | リリース前・定期監査 | 常時・イベント駆動型 |
| 主体 | 人間中心+自動化 | AIエージェント主導 |
| 活用先 | 技術改善 | 経営・規制対応判断 |
特に重要なのは、**自律型AIエージェント自身がレッドチームとして機能する世界**です。Microsoftや富士通が示しているように、攻撃AIと防御AIを常時競わせる構造は、人間の想定を超える脆弱性の発見を可能にします。これは評価の高度化であると同時に、評価コストの構造的削減も意味します。
また、2027年には規制対応の成熟度も明確な差を生みます。EU AI Actや日本のAI事業者ガイドラインは、単なるチェックリスト遵守ではなく、敵対的テストの継続性と説明可能性を求めています。**成熟度の高い組織ほど、レッドチーミングの結果をそのまま監督当局や取引先に提示できる状態**を整えています。
成熟度モデルの最上位では、レッドチーミングは「守り」ではなく「信頼を証明する仕組み」になります。AIが自律的に働く時代において、安全性を証明できる組織だけが高度なAI活用を社会から許容される。その分岐点が2027年であり、成熟度モデルは単なる評価軸ではなく、未来へのロードマップとして機能し始めているのです。
参考文献
- Microsoft:Assess Agentic Risks with the AI Red Teaming Agent in Microsoft Foundry
- Japan AISI:AI セーフティに関するレッドチーミング手法ガイド(第1.10版)
- PwC Japan:AIサービスのリスクとAIレッドチーム
- GMOサイバーセキュリティ by イエラエ:レッドチームとは?レッドチーム演習の効果や基本戦略を解説
- Fujitsu:Fujitsu develops world’s first multi-AI agent security technology
- NEC:Cotomi Act1.0