AIの進化が加速する一方で、「自分のデータはどこで、どう使われているのか」と不安を感じたことはありませんか。個人情報保護や企業データの機密性がこれまで以上に重視される中、従来のビッグデータ型AIには限界が見え始めています。
こうした課題に対する現実的な解として注目されているのが、フェデレーテッドラーニング(連合学習)です。データを一箇所に集めるのではなく、データのある場所でAIを学習させ、知識だけを共有するという発想は、プライバシーと高度なAI活用を両立させる切り札として、医療・金融・自動車など幅広い分野で社会実装が進んでいます。
本記事では、AIに関心のある方に向けて、フェデレーテッドラーニングの基本から2026年時点の最新技術動向、市場規模、日本独自の戦略、そしてLLMとの融合までを体系的に整理します。なぜ今この技術が不可欠なのか、読み終える頃にはその全体像と将来性がクリアに見えてくるはずです。
中央集権型AIの限界と分散型知能へのシフト
中央集権型AIは、膨大なデータを一箇所に集め、高性能な計算資源で一気に学習させることで進化してきました。ビッグデータとクラウドの時代においては極めて合理的なアプローチでしたが、2026年現在、その前提条件そのものが揺らいでいます。データを集めれば集めるほど、法的・倫理的・社会的リスクも集中するという構造的な限界が、もはや看過できなくなっているからです。
欧州のGDPRや米国のHIPAA、中国の個人情報保護法(PIPL)に代表されるように、個人データや機密情報の越境移転や集中管理に対する規制は年々厳格化しています。欧州データ保護監督機関(EDPS)も、中央集権的なデータ処理は単一障害点や濫用リスクを内包すると指摘しています。これにより、技術的には可能でも、社会的に許容されないAI活用が急増しているのが現実です。
| 観点 | 中央集権型AI | 分散型知能 |
|---|---|---|
| データの扱い | 一箇所に集約 | 各拠点に保持 |
| 法規制対応 | 制約が大きい | 比較的柔軟 |
| 障害リスク | 集中・致命的 | 局所的 |
こうした限界を背景に注目されているのが、知能そのものを分散させるという発想です。フェデレーテッドラーニングに代表される分散型知能では、生データを動かさず、モデルだけが各拠点を巡回します。Googleが提唱した「モデルをデータへ」という考え方は、中央集権型AIの前提を根底から覆しました。知性は共有するが、データの主権は手放さないという設計思想が、現代社会の要請と合致しています。
実際、医療や金融の現場では、データを外部に出せないことがAI導入の最大の障壁でした。分散型知能はこの制約を前提条件として受け入れ、その上で全体最適を実現しようとします。IBMによれば、分散学習は単なるプライバシー対策ではなく、組織間の信頼を技術で担保する仕組みでもあります。
中央集権型AIの限界は、性能の問題ではありません。社会と摩擦を起こさずに拡張できない点にこそ本質があります。分散型知能へのシフトは、効率を多少犠牲にしてでも、持続可能性と信頼性を優先するという価値観の転換を意味しています。AIが社会基盤になるための条件が、今まさに書き換えられているのです。
フェデレーテッドラーニングの基本的な仕組み
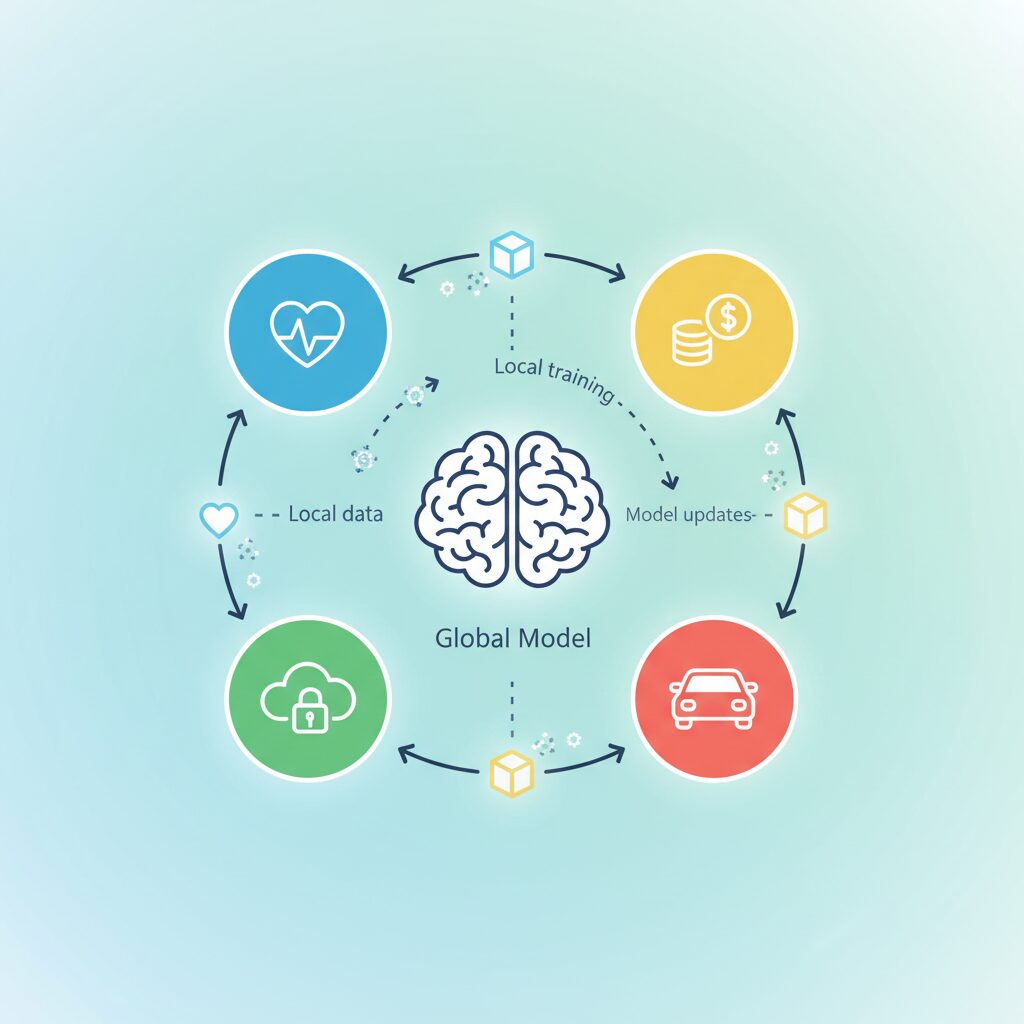
フェデレーテッドラーニングの基本的な仕組みは、従来の機械学習とは発想が逆転しています。大量のデータを一箇所に集めるのではなく、学習モデルそのものをデータのある場所へ配布する点が最大の特徴です。この考え方は、Googleの研究チームが2015年に提唱して以降、プライバシー保護と実用性を両立する手法として発展してきました。
まず中央のサーバーで初期化されたグローバルモデルが用意され、それがスマートフォンや企業サーバー、医療機関のシステムなど、複数のクライアントへ配信されます。各クライアントは、自身が保有するローカルデータのみを使ってモデルを学習します。この過程で生データが外部へ送信されることはなく、外部に共有されるのは学習結果であるパラメーター情報だけです。
| フェーズ | 行われる処理 | データの扱い |
|---|---|---|
| モデル配布 | 中央サーバーが初期モデルを配信 | 生データは移動しない |
| ローカル学習 | 各端末で個別に学習 | 端末内で完結 |
| 集約 | 更新パラメーターを統合 | 統計的情報のみ共有 |
集約フェーズでは、クライアントから送られてきた更新情報を平均化する「FedAvg」と呼ばれる手法が広く用いられてきました。IBMやGoogle Cloudによれば、この方法は計算コストと精度のバランスに優れ、数百万台規模のデバイス参加にも耐えられることが確認されています。2026年現在では、通信遅延や端末性能の差を考慮した非同期型の集約も標準的になりつつあります。
重要なのは、このサイクルが一度で終わらない点です。モデル配布、ローカル学習、集約という流れを何度も繰り返すことで、個々のデータを一切公開することなく、全体として高精度なAIモデルが育っていく仕組みになっています。欧州データ保護監督機関(EDPS)も、この反復構造こそがGDPR下での実用AIを可能にした核心だと指摘しています。
このようにフェデレーテッドラーニングは、単なる分散処理ではなく、データ主権を守るために設計された学習プロトコルです。モデルが移動し、知識だけが集約されるという構造を理解することが、この技術を正しく評価する第一歩になります。
集中型・P2P・階層型に進化する学習トポロジー
フェデレーテッドラーニングは、単一の仕組みではなく、学習ノード同士をどのようにつなぐかという「トポロジー」の進化によって実用性を大きく広げてきました。2026年時点では、集中型・P2P型・階層型という三つの構成が併存し、用途や制約条件に応じて使い分けられています。トポロジーの選択は、精度だけでなく、信頼性・通信効率・ガバナンスに直結する重要な設計判断です。
| トポロジー | 特徴 | 適した環境 |
|---|---|---|
| 集中型 | 中央サーバーが全体を集約 | 安定した通信と統制が必要な組織 |
| P2P型 | ノード間で直接モデル共有 | 自律分散・サーバー非依存 |
| 階層型 | 中間ノードで段階的に集約 | 大規模・地理分散環境 |
最も広く使われているのが集中型です。Googleが初期に提唱した方式でもあり、スマートフォン数百万台からの更新を中央で統合する設計は、アルゴリズム検証や品質管理の面で優れています。欧州データ保護監督機関(EDPS)によれば、クロスデバイス型の大規模運用では、集中型が依然として標準とされています。一方で、単一障害点や運営主体への信頼集中という課題も顕在化しています。
その反動として注目されているのがP2P型です。中央サーバーを置かず、デバイス同士が直接モデル更新を交換するため、特定組織への依存を避けられます。近年の分散最適化研究やDec-LoRAのような手法により、サーバーレスでも実用的な収束が可能になりました。通信インフラが限定的な地域や、DAO的な自律ネットワークとの親和性が高い点が評価されています。
さらに現実解として広がっているのが階層型です。エッジ端末、地域拠点、中央拠点という多段構造で学習を行うことで、通信量を抑えつつスケールさせます。NTTのIOWN構想に基づく実証では、600km離れた拠点間でもローカル比86%の学習効率が報告されており、物理的距離がボトルネックにならないことが示されました。
重要なのは、これらが競合ではなく補完関係にある点です。医療コンソーシアムでは階層型、消費者向けサービスでは集中型、次世代Webやエッジ連携ではP2P型というように、目的別の最適配置が進んでいます。トポロジーの進化は、フェデレーテッドラーニングを単なる技術から、社会実装可能な知能インフラへと押し上げる原動力になっています。
3つの主要分類とクロスデバイス/クロスサイロの違い
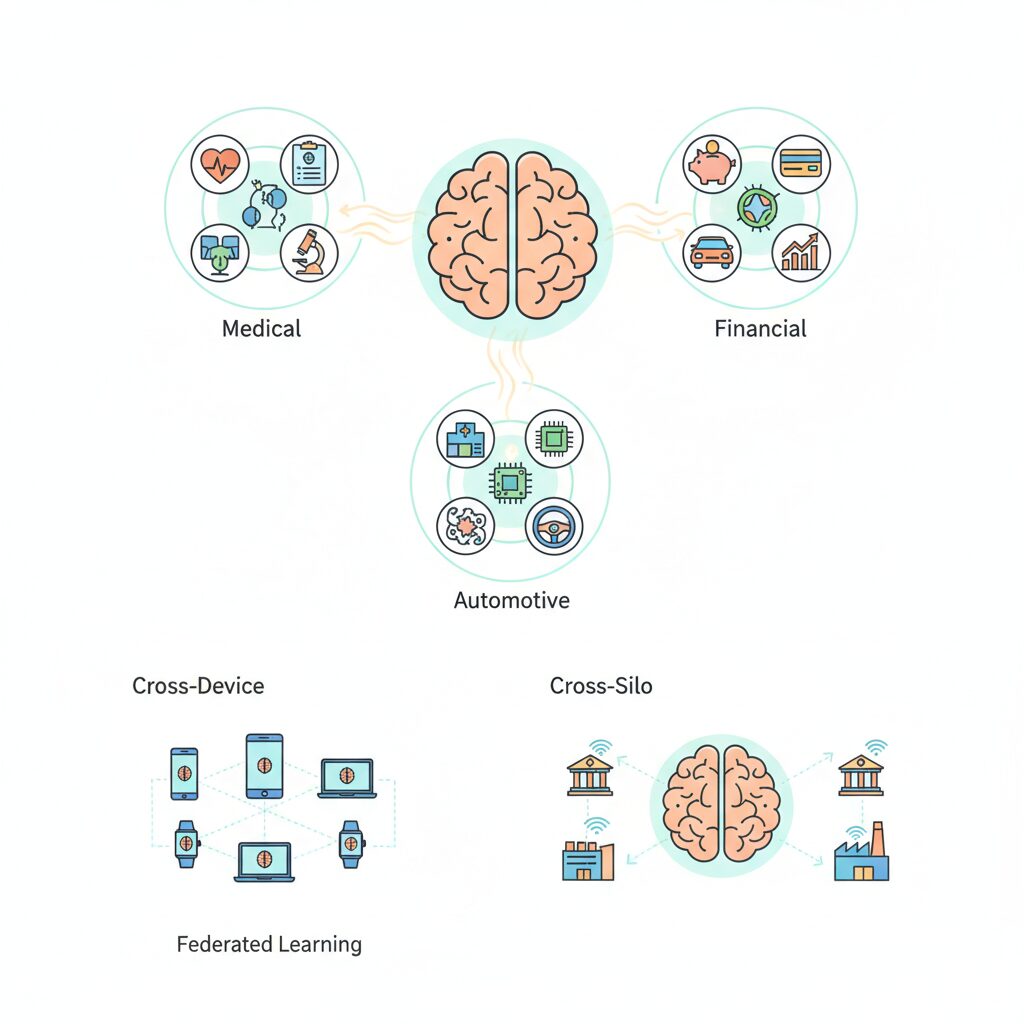
フェデレーテッドラーニングは一枚岩の技術ではなく、データの重なり方と組織間の関係性によって明確に分類されます。2026年時点で実務・研究の双方で共通理解となっているのが、横断的、縦断的、そしてフェデレーテッド転移学習の三分類です。IBMやGoogleの技術解説でも、この整理が基本構造として採用されています。
横断的フェデレーテッドラーニングは、特徴量は共通だがサンプルが異なるケースを扱います。スマートフォンの文字入力予測や、複数病院にまたがる共通疾患の診断モデルが代表例です。Googleによれば、数百万台規模の端末から学習する場合でも、生データを集約せずに精度を向上できる点が最大の利点とされています。
一方、縦断的フェデレーテッドラーニングは、同一の個人や企業を指しながら、各組織が異なる属性情報を保有している状況で威力を発揮します。金融機関と小売業が連携する与信モデルが典型で、IBMの事例分析では、個人情報を開示せずにスコア精度を改善できたと報告されています。
| 分類 | データの重なり | 主な用途 |
|---|---|---|
| 横断的FL | 特徴量が共通、サンプルが異なる | モバイルAI、医療画像解析 |
| 縦断的FL | サンプルが共通、特徴量が異なる | 金融与信、不正検知 |
| FL転移学習 | 双方の重なりが限定的 | 地域間・業種間の知識移転 |
三つ目のフェデレーテッド転移学習は、サンプルも特徴量も十分に一致しない状況を前提とします。医療過疎地域や新興市場など、データが極端に少ない環境で既存モデルの知識を安全に移転するための手法として、近年注目度が高まっています。
これらの分類と並んで重要なのが、運用規模によるクロスデバイスとクロスサイロの違いです。クロスデバイスは数百万台規模の個人端末を対象とし、通信断や端末性能のばらつきを前提に設計されます。AppleやGoogleの消費者向けAIがこの典型です。
対照的にクロスサイロは、病院、銀行、研究機関など少数だが信頼関係のある組織を結びます。European Data Protection Supervisorの分析によれば、2025年以降は医療コンソーシアムや金融ネットワークでのクロスサイロ型が急速に定着し、法規制を超えた共同学習の現実解となっています。
どの分類とどの運用形態を選ぶかは、技術の問題ではなく戦略の問題です。データの構造、参加者の関係性、規制環境を正しく見極めることが、フェデレーテッドラーニングを価値創出へと導く分岐点になります。
差分プライバシーと暗号技術が支える信頼性
フェデレーテッドラーニングが社会に受け入れられるための最大の前提条件は、「本当に信頼できるのか」という問いに技術で答えられるかどうかです。その中心にあるのが、差分プライバシーと暗号技術を組み合わせた多層的な防御設計です。単にデータを送らないだけでは不十分であり、学習結果そのものから個人情報が推測されるリスクをどう抑えるかが、2026年時点の重要な論点になっています。
差分プライバシーは、モデル更新時の勾配や重みに統計的ノイズを加えることで、特定の個人データが学習に使われたかどうかを理論的に判別不能にする仕組みです。欧州のデータ保護機関やGoogleの研究チームによる長年の検証により、プライバシー強度を示すε(イプシロン)を管理しながらも、実用精度を維持できる設計指針が確立されてきました。**2026年の実装では、固定ノイズではなく、学習段階やデータ分布に応じてノイズ量を動的に調整する手法が標準化されています。**
一方で、ノイズだけでは防げないのが、サーバーや通信経路そのものを信頼できない場合のリスクです。そこで暗号技術が決定的な役割を果たします。秘密マルチパーティ計算や準同型暗号を用いれば、集約サーバーであっても個々のクライアントの更新内容を復号できません。IBMやNTTの公開資料によれば、クロスサイロ型の金融・医療ネットワークでは、この「サーバー非信頼モデル」が導入の前提条件になりつつあります。
| 技術 | 守る対象 | 信頼性への寄与 |
|---|---|---|
| 差分プライバシー | 個人データの存在 | 理論保証に基づく再識別防止 |
| SMPC | 更新パラメータ | サーバーからの秘匿性確保 |
| 準同型暗号 | 計算プロセス | 暗号化状態のまま集約可能 |
| TEE | 実行環境 | ハードウェアレベルの隔離 |
さらに近年注目されているのが、信頼実行環境(TEE)との組み合わせです。MDPIのサーベイ論文によれば、RISC-Vベースのセキュアエンクレーブは、OSや管理者権限からも隔離された実行空間を提供し、暗号鍵や集約処理を安全に保持できます。**これにより「誰も中身を覗けない状態で学習が進む」という、従来は理論上の理想だった構造が現実のシステムとして成立しました。**
重要なのは、これらの技術が単独で使われるのではなく、重ね合わせによって信頼を構築している点です。差分プライバシーが統計的保証を与え、暗号技術が技術的・運用的な不正を排除し、TEEが最終的な実行の正当性を担保します。欧州データ保護監督機関(EDPS)は、この多層防御こそが将来の規制適合型AIの基準になると指摘しています。
結果として、フェデレーテッドラーニングは「信頼できるから使うAI」へと進化しました。**個人や組織が自らのデータ主権を手放すことなく、集合知の恩恵だけを享受できる**という設計思想は、単なる技術革新ではなく、AIと社会の関係性そのものを再定義しています。この信頼性の基盤こそが、分散型知能が長期的に機能するための不可欠な条件なのです。
市場規模と成長率から見る経済インパクト
フェデレーテッドラーニングの経済インパクトを測るうえで、市場規模と成長率は極めて重要な指標です。プライバシー規制の強化とAI活用の高度化という二つの潮流が重なり、この分野はAI市場の中でも特に高い成長角度を示しています。**単なる新技術ではなく、法規制対応コストを抑えながら価値創出を加速させる経済装置として評価され始めている点**が特徴です。
市場調査会社の分析によれば、フェデレーテッドラーニングのグローバル市場規模は2025年時点で約1.9億米ドルと推計され、2026年には約2.6億米ドルに達すると見込まれています。その後も高成長が続き、2033年には約24.7億米ドル規模に拡大する予測です。年平均成長率は38.1%とされ、これは生成AI関連市場の中でも上位水準に位置します。
| 指標 | 2025年 | 2026年 | 2033年予測 |
|---|---|---|---|
| 市場規模 | 約1.9億米ドル | 約2.6億米ドル | 約24.7億米ドル |
| 年平均成長率 | 38.1% | ||
この急成長の背景には、**データを集めないことで生まれる経済合理性**があります。GDPRやPIPLなどへの対応には、従来はデータ管理体制の再構築や越境データ移転コストが伴っていました。フェデレーテッドラーニングはこれらの固定費を構造的に削減し、複数組織が協調して学習する際の取引コストを大幅に下げます。欧州のデータ保護当局も、連合学習をプライバシーとイノベーションを両立させる実践的手段として位置づけています。
産業別に見ると、医療・ライフサイエンス分野が約24%と最大のシェアを占めています。医療分野単体でも2034年には約1.41億米ドル規模に成長すると予測されており、比較的安定した16.5%の成長率が見込まれています。これは景気変動の影響を受けにくい医療需要と、厳格な個人情報保護要件が同時に存在するためです。
地域別では北米が依然として最大市場ですが、注目すべきはアジア太平洋地域です。特に日本を含む同地域では二桁成長が続いており、少子高齢化や労働力不足を背景に、**分散した産業データを活用するAI投資が中長期の成長戦略として組み込まれている**点が経済的な追い風となっています。
企業規模の観点では、2025年時点で大企業の約60%がすでに導入済みである一方、中小企業の採用率も年率11%で増加しています。オープンソース基盤の普及により初期投資が下がり、これまでAI投資が難しかった層にも市場が広がりつつあります。**高成長率と裾野の拡大が同時進行している点**こそが、フェデレーテッドラーニングがもたらす経済インパクトの本質だと言えるでしょう。
日本におけるソブリンAI戦略とIOWNの役割
日本におけるソブリンAI戦略は、単に国産モデルを開発する取り組みにとどまらず、データ主権・計算資源・通信基盤を一体で自立させる国家レベルの設計思想として進められています。背景には、AIが社会インフラ化する中で、**学習データや推論結果が国外プラットフォームに依存するリスクが、経済安全保障上の課題として顕在化している**という認識があります。
内閣府や経済産業省の方針に基づき、2026年時点で日本政府は総額約60億ドル規模の投資を通じて、半導体からネットワーク、AI基盤までの垂直統合を推進しています。金融メディアや産業アナリストによれば、この規模は単年度の研究開発費ではなく、長期的な主権確保を前提としたインフラ投資として位置づけられています。
その中核を担うのが、NTTが主導するIOWN構想です。IOWNのオールフォトニクス・ネットワークは、電気信号を光に置き換えることで、従来のネットワークが抱えていた遅延や消費電力の制約を根本から刷新します。**フェデレーテッドラーニングのように頻繁なモデル更新を伴う分散学習では、通信遅延そのものが性能を左右するボトルネックとなるため、IOWNは戦略的に不可欠な存在**です。
NTT西日本が実施した実証では、約600km離れた分散データセンター間でも、ローカル環境比で86%の学習効率を達成しました。これは、地理的制約を受けずに国内各地の産業データを統合できる可能性を示しており、地方の製造業や医療機関をAI進化の輪に組み込む現実的な道筋を描いています。
| 要素 | 役割 | ソブリンAIへの寄与 |
|---|---|---|
| 国産半導体 | AI計算基盤の国内供給 | 演算能力の外部依存を低減 |
| IOWN APN | 超低遅延・低消費電力通信 | 分散学習の実用性を確保 |
| 国産LLM | 日本語・産業知識に最適化 | 文化・法制度への適合 |
特に重要なのは、IOWNが「中央集権型クラウド」への逆戻りを防ぐ点です。計算と学習を各現場に分散させたまま、高速に知識だけを循環させることで、**データを国内に留めたまま全国規模でAIを進化させるという、ソブリンAIの理想形を技術的に支えています**。
この構造は、人口減少や地域間格差といった日本固有の課題とも親和性が高く、専門家の間では「通信インフラそのものが知能を媒介する時代への転換点」とも評されています。IOWNは単なる高速ネットワークではなく、日本の主権AI戦略を現実の産業競争力へと変換する、不可欠な基盤として機能し始めています。
LLMとフェデレーテッドラーニングの融合がもたらす変化
大規模言語モデル(LLM)とフェデレーテッドラーニングの融合は、AIの学習方法そのものを根底から変えつつあります。従来のLLMは、巨大なデータを一か所に集めて学習する中央集権型が前提でしたが、2026年時点ではその前提が崩れ始めています。モデルは巨大なまま、データは分散したまま知識だけを共有するという新しいアプローチが、現実的な選択肢として確立されてきました。
この転換を可能にした最大の要因が、LoRAに代表されるパラメーター効率的ファインチューニング技術です。米国のACL関連研究によれば、LLM全体を更新するのではなく、低ランク行列のみを学習・共有することで、通信量を数千分の一に削減できることが示されています。これにより、数百億〜数千億パラメーター規模のLLMであっても、フェデレーテッド環境での実運用が現実的になりました。
この仕組みは単なる効率化にとどまりません。各組織やデバイスが持つ文脈依存の知識を、外部に漏らさずモデルへ反映できる点に本質的な価値があります。医療機関であれば診療記録、企業であれば社内文書や設計思想といった極めて秘匿性の高いデータを、学習対象として安全に活用できるようになります。
| 観点 | 従来型LLM学習 | フェデレーテッドLLM |
|---|---|---|
| データの扱い | 中央に集約 | 各拠点に保持 |
| プライバシーリスク | 高い | 大幅に低減 |
| パーソナライズ性 | 限定的 | 文脈ごとに最適化 |
実際のプロダクトでも変化は顕著です。Appleの2025〜2026年版Apple Intelligenceでは、端末上での軽量学習と、プライベートクラウドを組み合わせたハイブリッド構成が採用されています。Appleの研究公開によれば、独自の分散MoE構造により、同期オーバーヘッドを最大87.5%削減しつつ、高度な自然言語理解を実現しています。ユーザーの会話履歴が外部に送信されない点は、フェデレーテッドLLMの象徴的な成功例と言えます。
日本においても、この融合は戦略的意味を持ちます。東京科学大学と産総研が開発した国産LLM「Swallow」は、企業や自治体が保有する日本語特有の業務データを、フェデレーテッドに微調整する基盤として活用されています。海外モデルに依存せず、日本語文脈と主権データを守ったまま知能を進化させるという点で、ソブリンAIの中核技術になりつつあります。
今後、フェデレーテッドLLMは「巨大モデルを共有する」段階から、「知識の差分を安全に循環させる社会インフラ」へと進化していきます。Gartnerが指摘する自律型AIエージェントの普及と組み合わさることで、各エージェントが個人や組織の代理人として学習し、その成果だけを持ち寄る世界が現実味を帯びています。LLMとフェデレーテッドラーニングの融合は、性能向上の手段ではなく、信頼を前提としたAI活用の新しい常識を形作り始めています。
医療・金融・自動車分野で進む具体的ユースケース
フェデレーテッドラーニングが最も実務的な価値を発揮しているのが、医療・金融・自動車という高規制かつ高リスクな分野です。これらの領域では、データを集約できないという制約そのものが前提条件であり、分散型知能は現実解として受け入れられています。
医療分野では、患者データの秘匿性を維持したまま診断精度を高める用途が急速に広がっています。日本やベトナムで進められている糖尿病網膜症のスクリーニングでは、各医療機関が保有する眼底画像を外部に出さずに共同学習を実施しています。NIDEK社のプロジェクトでは、Vision Transformerを用いたフェデレーテッド学習により、**感度94%以上という臨床水準を満たす精度**を達成しました。欧州データ保護監督機関も、こうした仕組みはGDPRのデータ最小化原則と整合的であると評価しています。
| 分野 | 代表的ユースケース | 実務的効果 |
|---|---|---|
| 医療 | 疾患スクリーニング、創薬 | プライバシー維持と診断精度の両立 |
| 金融 | 不正取引検知、与信管理 | 詐欺検知率向上と法規制対応 |
| 自動車 | 自動運転支援、安全学習 | 地域全体の事故リスク低減 |
金融分野では、フェデレーテッドラーニングは「信頼を共有するためのAI」として機能しています。銀行や保険会社は個人情報保護法やPIPLの制約により取引データを直接共有できませんが、クロスサイロ型の共同学習により最新の詐欺パターンだけを共有しています。米国および日本の金融ネットワークでは、**金融系AIプロジェクトの約20%が不正検知を目的とした連合学習**に割り当てられており、単独行では見逃されがちな巧妙な不正を早期に検出できる点が評価されています。IBMによれば、複数機関が参加するモデルほど新規詐欺への追従速度が向上することが確認されています。
自動車分野では、フェデレーテッドラーニングはリアルタイム安全性を高める基盤技術となっています。自動運転車は日々膨大な走行データを生成しますが、その多くは位置情報や周辺映像を含むため集中管理が困難です。横浜市で行われた実証実験では、各車両が体験した「ヒヤリハット」事例をモデル更新として共有し、他車両の制御モデルに即時反映しました。その結果、**特定交差点での危険挙動予測精度が大幅に改善**したと報告されています。トヨタや日産が導入を進める物理AIやVLAモデルも、全国の車両知見を秘匿性を保ったまま学習し続ける構造を採っています。
セキュリティ脅威と最新の防御アプローチ
フェデレーテッドラーニングは生データを共有しないという特性から、安全性が高いと認識されがちですが、2026年現在ではそれ自体が高度な攻撃対象になっています。特に研究コミュニティや産業界で深刻視されているのが、**悪意ある参加者が学習プロセスに介入し、モデルの挙動を歪めるポイズニング攻撃**です。欧州データ保護監督機関(EDPS)も、分散学習におけるセキュリティはプライバシーとは別軸で設計すべき課題だと指摘しています。
中でも危険性が高いのがバックドア攻撃です。これは通常の入力では正しく動作しながら、特定のトリガー条件下のみ誤判定を引き起こすもので、医療診断や金融不正検知のような高信頼性が求められる領域では致命的になり得ます。NeurIPSで報告された研究では、**短期間しか参加しないクライアントであっても、永続的なバックドアをモデルに残せる**ことが示され、従来の単純な異常検知では防ぎきれない実態が明らかになりました。
| 脅威の種類 | 攻撃の特徴 | 2026年時点の防御アプローチ |
|---|---|---|
| バックドア攻撃 | 特定条件下のみ誤作動 | FDCRによる異常更新の検出と再スケーリング |
| 階層型ポイズニング | 特定層を狙い持続性を確保 | 層別の耐故障集約アルゴリズム |
| ビザンチン障害 | 故障・悪意ある勾配送信 | Sentinelによるリモートアテステーション |
防御技術の中核を成しているのが、**統計的・暗号的手法とハードウェア信頼基盤の融合**です。例えばFDCRは、各クライアントから送られる更新をフィッシャー情報量の観点で解析し、通常の学習分布から乖離した挙動を示す更新を自動的に無効化します。これは単なる外れ値除去ではなく、モデル内部の感度構造を考慮する点に特徴があります。
さらに注目されているのがSentinelに代表されるリモートアテステーション型の防御です。これはTrusted Execution Environment(TEE)上で学習が正しく行われていることを暗号的に証明する仕組みで、IoTデバイスのような物理的に侵害されやすい端末でも有効とされています。MDPIのサーベイ論文によれば、**TEEを組み込んだフェデレーテッドラーニングは、攻撃成功率を大幅に低減する**ことが実験的に確認されています。
この考え方はSecurity by Designとして定着しつつあり、金融や医療のクロスサイロ型プロジェクトでは事実上の前提条件になっています。フェデレーテッドラーニングが社会インフラとして広がるほど、攻撃と防御の水準も同時に引き上げられます。**分散知能の信頼性は、最新の防御アプローチを継続的に実装できるかどうかにかかっている**と言えるでしょう。
2026年以降に残された課題と今後の展望
2026年以降のフェデレーテッドラーニングには、社会実装が進んだがゆえに顕在化する課題が残されています。最大の論点は、技術そのものではなく、分散した知能をいかに持続可能な形で運用・統治するかという点にあります。欧州データ保護監督機関(EDPS)が指摘するように、プライバシー保護技術が高度化するほど、運用の複雑性と説明責任の重要性が増していきます。
まず避けて通れないのが、デバイスとデータの不均一性です。計算性能や通信品質、データ分布が大きく異なる環境では、学習効率やモデル品質にばらつきが生じます。2026年時点では非同期集約やクライアントサンプリングが実用段階にありますが、2030年に向けては自律的に学習戦略を切り替える適応型制御が求められます。Gartnerも、AIシステムが環境変化に応じて自己最適化する方向性を示しています。
次に、通信とエネルギー効率の問題です。LoRAや勾配圧縮によって通信量は大幅に削減されましたが、数百億パラメーター級のモデルでは依然としてコストが支配的です。NeurIPSで報告されたFedLUARのような更新リサイクル技術は、通信量を約17%に抑えながら精度を維持できるとされており、今後は「通信を前提にしない学習設計」が競争力の源泉になります。
| 残された課題 | 背景 | 今後の展望 |
|---|---|---|
| 不均一性の克服 | デバイス性能・データ品質の差 | 自律適応型・非同期FLの標準化 |
| 通信・電力コスト | LLMの巨大化 | 更新削減・光通信インフラの活用 |
| 人材・運用負荷 | 専門知識への依存 | ノーコード化とマネージドサービス |
さらに深刻なのが、中小企業への普及です。市場調査では、52%の中小企業が専門人材不足を理由に導入を遅らせているとされています。ここで鍵となるのが、オープンソース基盤とマネージド型サービスの拡充です。Flower Labsなどの取り組みは、フェデレーテッドラーニングを「高度技術」から「使えるインフラ」へ変える転換点になると評価されています。
展望として注目されるのは、AIエージェントとの融合です。2028年までに企業アプリケーションの3分の1に自律型エージェントが組み込まれるという予測もあり、これらのエージェントがフェデレーテッドな形で学習し合うことで、個人データを守りながら集団知を形成します。2026年以降のフェデレーテッドラーニングは、単なる学習手法ではなく、社会的知性を支える基盤として進化していくと考えられます。
参考文献
- Google Cloud:Federated learning: what it is and how it works
- IBM:What Is Federated Learning?
- European Data Protection Supervisor:Federated Learning | TechSonar
- MarketMind Partners:Federated Learning Market Size, Share, Growth, And Industry Analysis By 2033
- NTT:ニュースリリース一覧
- Apple Machine Learning Research:Updates to Apple’s On-Device and Server Foundation Language Models