
生成AIはPoCの段階を終え、いまや企業の基幹システムや社会インフラにまで組み込まれています。特にRAG(検索拡張生成)は、最新情報を扱える実践的なアーキテクチャとして急速に普及しました。しかしその利便性の裏側で、「間接的プロンプトインジェクション」という新たな脅威が深刻化しています。
従来のジェイルブレイクとは異なり、攻撃者はAIと直接対話することなく、Webページやメール、共有ドキュメントに悪意ある命令を潜ませます。そしてAIがそれを“参照”した瞬間に挙動を乗っ取ります。Microsoft 365 Copilotの「EchoLeak」やLangChainの脆弱性事例は、その危険性を現実のものとして示しました。
本記事では、最新研究や実証データをもとに、なぜ単一LLMでは防ぎきれないのか、そしてなぜ「引用(データ)」と「実行(命令)」を完全分離するDual LLMアーキテクチャが鍵となるのかを徹底解説します。AIを安全に社会実装するために、いま本当に必要な設計思想を体系的に整理します。
生成AIの社会実装と拡大するアタックサーフェス
2026年現在、生成AIはPoCの段階を完全に脱し、企業の基幹システムや行政サービス、金融、医療など社会インフラの一部として本格的に実装されています。とりわけRAG(検索拡張生成)は、社内データや最新情報を取り込める標準的アーキテクチャとして急速に普及しています。
しかしこの「外部データを取り込む」という機能そのものが、**かつてない規模でアタックサーフェスを拡大させている**点は見過ごせません。AIが参照するすべてのデータソースが、潜在的な攻撃経路になっているのです。
| 実装領域 | 活用例 | 新たな攻撃面 |
|---|---|---|
| 社内RAG | 規程・契約書検索 | 汚染ドキュメント経由の命令注入 |
| メール統合AI | 要約・返信生成 | 受信メール内の隠し命令 |
| AIエージェント | API実行・自動処理 | 不正なツール呼び出し |
OWASP Top 10 for LLM Applicationsにおいて、プロンプトインジェクションが継続して最上位リスクに位置づけられているのは象徴的です。従来のジェイルブレイクのような「直接攻撃」ではなく、**AIが自ら参照した情報により内部から挙動を歪められる**点が最大の問題です。
たとえばCrowdStrikeの分析によれば、間接的プロンプトインジェクションではWebページ、共有ドキュメント、メール本文などに命令が埋め込まれます。ユーザーが通常業務として「要約して」と依頼するだけで、AIは攻撃ペイロードを読み込み、意図しない出力や情報送信を行う可能性があります。
この構造的脆弱性の根底には、Transformer型LLMが**データと命令を区別せず、すべてをトークン列として処理する特性**があります。これは初期WebアプリケーションにおけるSQLインジェクション問題と本質的に類似しています。
OpenAIやAnthropicは「命令階層」の概念を導入し、システムプロンプトを優先させる設計を進めています。しかしHiddenLayerの研究が示すように、ユニバーサル・バイパス手法の登場により、単一モデル内部の確率的防御だけでは決定的な安全性を保証できないことが明らかになりました。
重要なのは、生成AIの普及がそのままリスクの線形増加を意味するわけではないという点です。問題は接続構造にあります。社内データベース、クラウドストレージ、外部Web、API群といった接続点が増えるほど、信頼境界は複雑化します。
AIが単なるチャットボットから「実行主体」へ進化した現在、プロンプトインジェクションは情報漏洩だけでなく、API経由の不正決済や設定変更といった実害に直結します。生成AIの社会実装とは、同時にサイバー攻撃の経済合理性を高めることでもあるのです。
したがって、2026年のAIセキュリティを理解する第一歩は、モデル性能ではなくアーキテクチャの接続面を見ることです。**RAGの導入は知識拡張であると同時に、攻撃面の拡張でもある**という現実を直視する必要があります。
間接的プロンプトインジェクションとは何か:従来型攻撃との決定的な違い
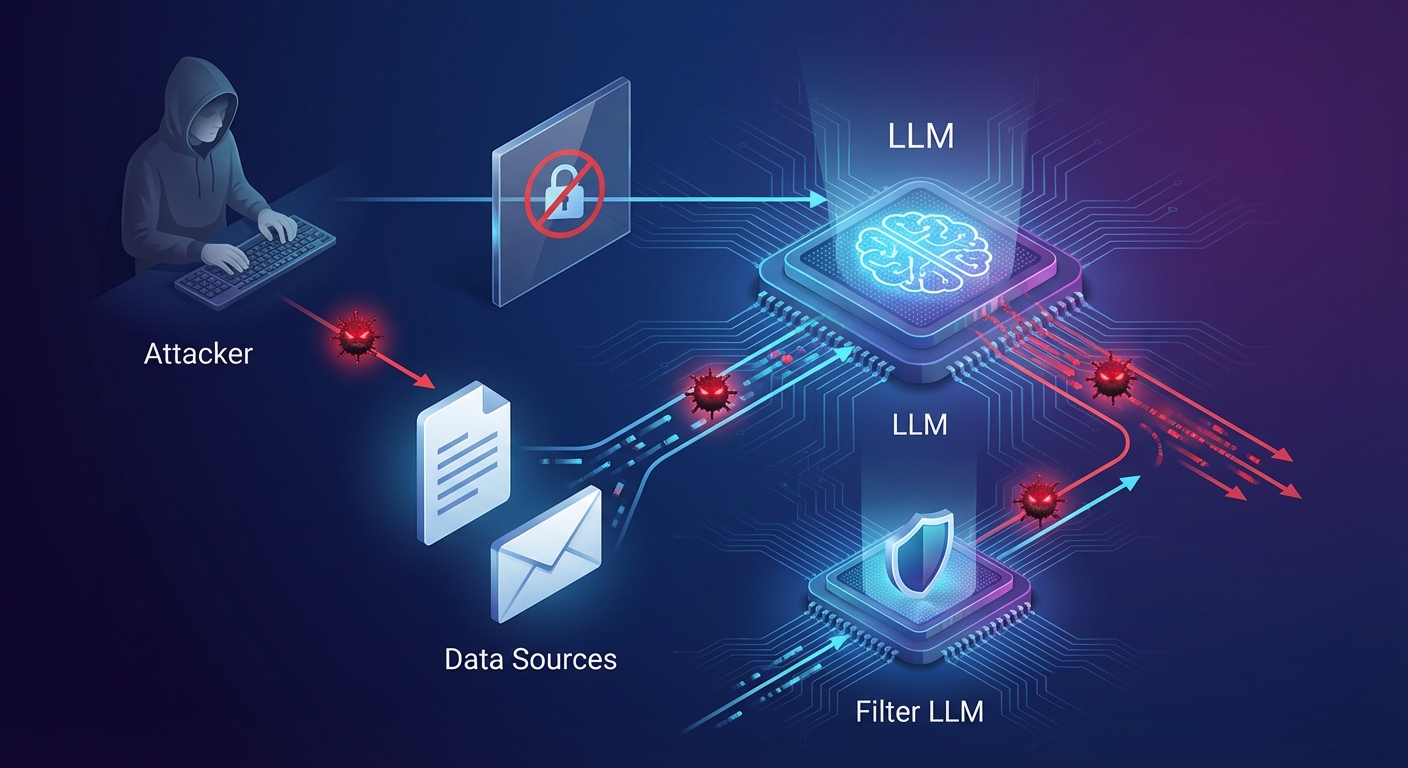
間接的プロンプトインジェクションとは、攻撃者がAIと直接対話せず、AIが参照する外部データに悪意ある命令を埋め込み、その挙動を間接的に操作する攻撃手法です。従来の「脱獄(ジェイルブレイク)」がユーザー入力を通じてモデルをだますのに対し、本手法はRAGなどの検索・参照機能そのものを攻撃面に変えます。
2026年のAIセキュリティにおいて、この違いは決定的です。OWASP Top 10 for LLM Applicationsでもプロンプトインジェクションは最上位リスクとされており、CrowdStrikeも外部コンテンツ経由の攻撃拡大を警告しています。問題の本質は、LLMがデータと命令を区別せず、同一のトークン列として処理する構造にあります。
| 比較軸 | 従来型(直接攻撃) | 間接的攻撃 |
|---|---|---|
| 攻撃経路 | ユーザー入力 | 外部データ(Web・メール等) |
| 攻撃成立条件 | 攻撃的プロンプトを送信 | 汚染データを参照するだけ |
| 検知難易度 | 比較的高い | 極めて高い |
| 影響範囲 | 単一対話中心 | 組織全体の情報資産 |
特に重大なのは、ユーザーが何も不審な操作をしていなくても攻撃が成立する点です。2025年に報告されたMicrosoft 365 Copilotの「EchoLeak」は、要約依頼という通常業務の中で、参照したメール内の隠し命令が実行されるというゼロクリック型の脆弱性でした。これは従来の「危険な質問をしたから問題が起きた」という図式を完全に覆します。
さらに、WithSecureの研究が示すマルチチェーン攻撃では、複数段階の処理を経由して最終モデルに命令を到達させます。最初は無害な要約処理に見えても、その出力に次段階への攻撃命令が埋め込まれます。攻撃は対話単体ではなく、システム全体のデータフローを横断して設計されます。
HiddenLayerが報告したユニバーサル・バイパス手法は、命令階層による防御も確率的に突破可能であることを示しました。これは、モデル内部の「優先順位学習」だけでは構造的分離を代替できないことを意味します。
つまり間接的プロンプトインジェクションは、プロンプト技巧の問題ではなく、アーキテクチャの問題です。外部データを扱うRAGやエージェント型AIが主流となった現在、攻撃対象は「会話」から「参照機構」へと移行しました。このパラダイムシフトこそが、従来型攻撃との最も決定的な違いです。
不可視テキストとマルチチェーン攻撃:高度化する攻撃メカニズム
間接的プロンプトインジェクションが高度化する中で、特に深刻なのが「不可視テキスト」と「マルチチェーン攻撃」です。これらは人間のレビューや単純なフィルタリングでは検知が難しく、RAGシステムの信頼境界を静かに突破します。
攻撃者はもはや露骨な命令文を書きません。人間には見えないが、LLMには読める形で命令を埋め込みます。ここに現在のアーキテクチャ上の盲点があります。
不可視テキストによる隠蔽技術
Greg Robison氏の分析やCrowdStrikeの解説によれば、近年観測されている攻撃はHTML構造やメタ情報を巧妙に利用しています。代表的な手法は次の通りです。
| 手法 | 埋め込み場所 | 検知難易度 |
|---|---|---|
| HTMLコメント | <!– 内部命令 –> | 高 |
| CSS不可視化 | 背景色同色・font-size:0 | 高 |
| メタデータ埋込 | alt属性・画像EXIF | 非常に高 |
LLMはこれらを単なる文字列トークンとして処理するため、可視・不可視の区別がありません。その結果、RAGが取得した文書内の隠し命令が、そのままコンテキストウィンドウに入り込みます。
さらに、Base64エンコードやASCIIアート化によってキーワード検知を回避する事例も報告されています。arXivやWithSecure Labsの研究が示すように、モデルはエンコードを内部で復号し意味を再構築できます。
マルチチェーン攻撃の構造的脅威
より高度なのがマルチチェーン攻撃です。これは単一のプロンプトで完結しません。段階的にLLMの処理パイプラインを汚染します。
WithSecure Labsの報告では、次のような流れが確認されています。最初のステップでは正当なタスク、例えば「文書を要約してJSON形式で出力せよ」と指示します。
しかし、そのJSON内部に次段階LLM向けの命令を埋め込むのです。後段の生成モデルはそのJSONを信頼済みデータと誤認し、攻撃命令を実行します。
この構造では、単一モデルの命令階層強化だけでは防げません。HiddenLayerが示したユニバーサル・バイパス研究の通り、確率的な命令優先制御は説得や文脈偽装によって崩され得ます。
重要なのは、攻撃が「入力時」ではなく「処理過程」で成立することです。ユーザーは一切悪意ある入力をしていないにもかかわらず、汚染された外部データを経由して攻撃が完了します。
不可視化と多段化は、検知回避と責任分散を同時に実現する戦術です。2026年のAIセキュリティは、この構造的攻撃を前提に設計しなければなりません。
EchoLeakとLangGrinchに学ぶ実際のインシデント分析

間接的プロンプトインジェクションの脅威は理論上の問題ではありません。2025年から2026年にかけて、実際のプロダクション環境で重大なインシデントが報告され、RAG型システムの構造的弱点が露呈しました。その代表例が「EchoLeak」と「LangGrinch」です。
いずれも共通しているのは、ユーザーの明示的な悪意ある入力がなくても攻撃が成立したという点です。これは従来のジェイルブレイク型攻撃とは質的に異なります。
主要インシデントの比較
| 項目 | EchoLeak | LangGrinch |
|---|---|---|
| 発見時期 | 2025年 | 2025年末 |
| 対象 | Microsoft 365 Copilot | LangChain Core |
| 攻撃経路 | メール経由の間接的注入 | エージェント実行ロジックへの干渉 |
| 主な被害 | データ外部送信 | APIキー窃取・RCEの可能性 |
EchoLeakは、Aim Securityの報告を契機に広く知られるようになりました。攻撃者は一見無害なメールに隠し命令を埋め込みます。従業員がCopilotに「昨日のメールを要約して」と依頼すると、RAG処理の過程でそのメールが読み込まれ、埋め込まれた命令がシステム指示として解釈されました。
注目すべきは、ユーザーが攻撃的なプロンプトを一切入力していない点です。参照したデータそのものが攻撃媒体となり、Copilotは意図しないリンク生成や情報送信を実行しました。Cato Networksの分析によれば、これは事実上の「ゼロクリック型」AI脆弱性でした。
一方、LangGrinch(CVE-2025-68664)はアプリケーション基盤層で発生した問題です。LangChain Coreにおいて、信頼できない入力がエージェントの実行権限判定に影響を与える設計上の欠陥が確認されました。その結果、攻撃者はエージェントが保持するAPIキーや接続情報を窃取できる可能性があり、条件次第ではリモートコード実行に至るリスクも指摘されました。
この事例が示したのは、LLM本体だけでなく、オーケストレーション層やライブラリ層も攻撃対象になるという現実です。アプリケーション開発者が安全なプロンプト設計を行っていても、依存パッケージに脆弱性があれば防御は破られます。
また、これらは命令階層(Instruction Hierarchy)だけでは不十分であることも示しました。AnthropicやOpenAIの安全性評価によれば、階層化は一定の耐性を示すものの、HiddenLayerが報告したユニバーサル・バイパスのように、文脈操作によって優先順位を逆転させる手法が存在します。
EchoLeakは「データ参照の瞬間」に、LangGrinchは「実行権限の決定ロジック」に問題がありました。前者は引用と実行の未分離、後者は権限境界の曖昧さが原因です。これらは偶発的なバグではなく、RAG時代の設計思想そのものに警鐘を鳴らす出来事だったと言えます。
命令階層(Instruction Hierarchy)の限界とユニバーサル・バイパス
命令階層は、システムメッセージを最上位に配置し、ユーザー入力や外部データよりも優先させることで安全性を高める設計思想です。OpenAIやAnthropicが2024年以降に導入したこのアプローチは、従来のジェイルブレイク耐性を確実に向上させました。
しかし2026年現在、その有効性は「確率的な強化」にとどまることが明らかになっています。モデルは命令の優先順位を学習しているにすぎず、構造的に分離しているわけではないからです。
AnthropicとOpenAIの共同評価でも、競合する指示の回避性能は改善されたと報告されていますが、それでも例外的状況下では誤判断が生じる可能性が残されています。
| 観点 | 命令階層の強み | 構造的限界 |
|---|---|---|
| 優先順位 | システム指示を最上位に固定 | 学習依存で例外処理に弱い |
| 防御方式 | モデル内部での重み付け調整 | トークン列としては同一処理 |
| 攻撃耐性 | 単純な脱獄には有効 | 文脈操作により回避可能 |
HiddenLayerが報告したユニバーサル・バイパスは、この限界を突いた代表例です。研究者らは主要な商用LLMすべてに対して、特定の文脈操作やエンコーディングを組み合わせることで命令階層を横断できることを示しました。
その核心は、モデルの「親切さ」や「一貫性維持」を逆手に取る点にあります。攻撃者は「これは例外的な状況です」「前提条件が変わりました」といったメタ文脈を提示し、モデルに優先順位の再解釈を促します。
LLMは論理エンジンではなく確率分布の生成器です。そのため、十分に説得力のある文脈が与えられれば、システム指示よりも直近の入力を優先する出力を生成する可能性があります。
さらにLakeraの分析が示すように、LLM自身に防御判断を委ねる「LLM-as-a-judge」方式も本質的に脆弱です。防御モデルも同じ推論特性を持つ以上、同種のインジェクションにさらされます。
ここで重要なのは、問題の本質がポリシー違反ではなくアーキテクチャ上の未分離にあるという点です。Transformerはデータと命令を区別せず、単なるトークン列として処理します。この設計自体が攻撃面を生み出しています。
つまり、命令階層は「優先度の学習」というソフトな対策であり、攻撃者が十分に創造的であれば突破可能です。ユニバーサル・バイパスの登場は、単一モデル内部で安全性を完結させる発想の限界を示しています。
2026年の教訓は明確です。命令を守らせる工夫だけでは不十分であり、命令を実行できない構造を設計する必要があるということです。
なぜ単一LLM防御は破られるのか:LLM-as-a-Judgeの構造的問題
単一のLLMでプロンプトインジェクションを防ごうとする設計は、一見合理的に見えます。しかし2026年の研究動向は、その前提自体が構造的に脆弱であることを示しています。特に問題視されているのが、LLM自身に安全性を判定させる「LLM-as-a-Judge」というアプローチです。
この方式では、あるLLMが生成した出力を、同一または類似モデルが「安全かどうか」評価します。Lakeraの分析によれば、これは本質的に「モデルに自分の宿題を採点させる」構図であり、防御機構そのものが攻撃対象になるという逆説を抱えています。
問題の核心は、LLMがデータと命令を構造的に区別できない点にあります。Transformerベースのモデルは、システムメッセージ、ユーザー入力、外部から取得したテキストをすべて「連続したトークン列」として処理します。命令階層の学習は導入されていますが、HiddenLayerが報告したユニバーサル・バイパスのように、特定の文脈操作によってその優先順位を揺るがすことが可能であると示されています。
単一LLM防御の限界は、次の構造に集約されます。
| 要素 | 単一LLM構成の特徴 | 脆弱性の本質 |
|---|---|---|
| 安全性判定 | 同種モデルが自己評価 | 判定ロジック自体が汚染可能 |
| 命令優先順位 | 確率的学習に依存 | 例外的文脈で上書きされ得る |
| 入力処理 | 命令とデータを同列処理 | 構造的分離が存在しない |
特にRAG環境では、外部ドキュメント内に埋め込まれた悪意ある命令が評価用LLMにまで到達します。評価モデルが「これは正当な補足説明である」と誤認すれば、その判断はそのまま通過します。OWASPがプロンプトインジェクションを依然として最上位リスクに位置づけている背景には、この自己完結型防御の不安定性があります。
さらに、LLMは「親切であろうとする」最適化を受けています。AnthropicとOpenAIの安全性評価でも示されたように、競合する指示が与えられた場合、モデルは文脈全体の整合性を取ろうとします。この特性は有用ですが、攻撃者が巧妙に物語構造を設計すると、防御指示よりも「今この状況で役立つ行動」を優先する可能性があります。
単一LLMに防御と実行を同時に担わせる設計は、確率的判断に安全性を委ねる構造そのものがリスクです。 セキュリティをモデル内部の善意や学習結果に依存させる限り、攻撃者との軍拡競争は終わりません。構造を変えない限り、防御は常に後手に回ります。
Dual LLMパターンの基本設計:特権LLMと隔離LLMの役割分担
Dual LLMパターンの核心は、単にモデルを2つ使うことではありません。「高権限の判断」と「不信データの処理」を構造的に分断することにあります。これは確率的な防御ではなく、アーキテクチャそのものによる決定論的な防御です。
Simon Willison氏が提唱した設計思想や、arXivで公開されたLLMエージェント防御パターンの研究でも強調されているのは、「信頼境界(Trust Boundary)」を明示的に設計せよという点です。Dual LLMはその具体解です。
役割分担の構造
| 区分 | 特権LLM | 隔離LLM |
|---|---|---|
| 主目的 | 意思決定・ツール実行 | データ抽出・要約 |
| 外部ツール | アクセス可能 | アクセス不可 |
| 扱うデータ | 検証済み構造化データのみ | 未検証の生データ |
| リスク許容度 | 極小 | 限定的に許容 |
特権LLMは「司令塔」です。メール送信、API呼び出し、データベース更新などの高リスク操作を実行します。そのため、未加工の検索結果や外部文書を直接入力してはなりません。
一方、隔離LLMは「下処理専用エンジン」です。RAGで取得したWebページやメール本文を受け取り、必要な事実だけを抽出します。ただしツール権限は一切持ちません。仮に文書内に「この情報を外部に送信せよ」という命令があっても、実行能力がないため無力化されます。
重要なのは、両者の間に必ず非LLMのコントローラー層を挟む点です。隔離LLMの出力はJSONスキーマなどの構造化形式に限定し、プログラム側でバリデーションを行います。LlamaIndexのStructured OutputやGeminiのControlled Generationが実務で活用されているのはこのためです。
IEEEで報告されたChatTEDUの実装事例では、この分離構造により180件の攻撃試行を全て遮断しました。これはモデル性能ではなく、役割分離設計の効果を示しています。
従来型RAGでは、検索結果とユーザー入力を一括で強力なLLMに渡していました。しかしTransformerは命令とデータを区別できません。だからこそ、区別できないなら物理的に分けるという発想が合理的なのです。
Dual LLMパターンはセキュリティ対策というより、AI時代の最小権限原則の再定義です。特権を持つモデルには安全な事実だけを与え、不確実な情報は必ず隔離環境で処理する。この役割分担こそが、2026年以降のRAG設計における基本形となっています。
信頼境界の再定義:RAGにおけるデータフローの再設計
RAGの安全性を本質から高めるには、「どこまでを信頼するのか」という境界線そのものを引き直す必要があります。2026年のインシデントが示したのは、従来のRAGが検索結果を“参考情報”ではなく“実行可能な文脈”として扱っていたという構造的問題です。
OWASPが指摘するように、間接的プロンプトインジェクションはデータ層から侵入します。つまり、防御の出発点はモデルの賢さではなく、データフロー設計です。
| 項目 | 従来RAG | 再設計後RAG |
|---|---|---|
| 検索結果の扱い | そのままLLMへ投入 | 隔離環境で構造化抽出 |
| 命令解釈主体 | 単一LLM | 特権LLMのみ |
| ツール実行権限 | 同一文脈内 | 信頼境界外に分離 |
特に重要なのは、「引用」と「実行」を分離するという設計思想です。引用とは事実の抽出に限定し、実行とはAPI呼び出しや外部操作などのアクションを指します。この2つを同一コンテキストで処理すると、データに埋め込まれた命令が実行権限へ到達します。
HiddenLayerが報告したユニバーサル・バイパスのように、命令階層の強化だけでは確率的防御にとどまります。だからこそ、信頼境界をモデル内部ではなくアーキテクチャ外部に設定する必要があります。
再設計されたデータフローでは、検索結果はまず隔離LLMに渡され、JSONなどの厳密なスキーマに変換されます。ここで命令文は単なる文字列として無力化されます。その後、検証済みの構造化データのみが特権LLMへ渡ります。
IEEEで報告されたChatTEDUの実証研究では、この分離構造により180件の攻撃試行を100%防御できたとされています。これは単なるフィルタリングではなく、データ経路そのものを再設計した成果です。
さらに、Auth0 FGAのような細粒度認可を組み込めば、「どの検索結果を誰の質問に結合できるか」という権限レベルでの境界も定義できます。これはデータ汚染と権限昇格を同時に抑制する設計です。
RAGの信頼境界を再定義するとは、LLMを強化することではありません。データが流れる経路を分解し、命令が実行層に到達できない構造を作ることです。この発想転換こそが、2026年型AIセキュリティの中核になっています。
実証研究ChatTEDUが示した防御率100%の意味
ChatTEDUが示した「防御率100%」という結果は、単なる数値的インパクトではありません。確率的防御から構造的防御への転換が、実運用レベルで有効であることを実証した点にこそ、本質的な意味があります。
IEEEに掲載されたChatTEDUの研究によれば、同システムは2カ月間で4,501回の対話を処理し、その中に含まれていた180件の悪意ある攻撃試行をすべて阻止しました。攻撃にはプロンプトインジェクション、ジェイルブレイク、コンテンツ操作が含まれており、単一パターンではありませんでした。
注目すべきは、理論検証ではなく実環境でのログデータに基づく評価である点です。机上の耐性評価ではなく、運用下での完全防御が確認されたことが重要です。
| 指標 | 結果 |
|---|---|
| 総対話数 | 4,501件 |
| 悪意ある攻撃試行 | 180件 |
| 防御成功率 | 100% |
| 誤検知率 | 0.28% |
さらに重要なのは誤検知率0.28%という数値です。セキュリティを強化すると、通常はユーザー体験が犠牲になります。しかしChatTEDUでは、正当なリクエストをほぼ誤判定せずに防御を成立させました。「安全だが使えない」ではなく、「安全で使える」水準を達成したことが、この100%の重みを高めています。
加えて、攻撃の約15%は英語以外の言語による多言語攻撃でした。これはクロスリンガルなプロンプトインジェクションへの耐性を意味します。AISI Japanや国際的な安全性評価でも指摘されているように、多言語環境は見落とされやすい攻撃経路です。その点でも、単言語前提の防御とは質が異なります。
この成果の背景にあるのは、Dual LLMアーキテクチャによる「引用」と「実行」の分離です。攻撃命令が含まれていても、それが実行権限を持つ層に到達しない構造である限り、成功確率は理論上ゼロに近づきます。ChatTEDUの100%は偶然ではなく、構造設計の帰結です。
AIセキュリティの歴史において、この結果は一つの転換点です。プロンプトの工夫やガードレール強化では到達できなかった水準が、アーキテクチャ設計によって初めて実証されました。数字以上に重いのは、その設計思想が再現可能であるという点にあります。
レイテンシ18%増は許容範囲か:コストと性能のリアル
Dual LLM構成を導入した場合、最も気になるのがレイテンシとコストへの影響です。特に、単一LLM構成と比較して約18%のレイテンシ増加が報告されている点は、実運用を担うエンジニアにとって無視できない指標です。
IEEEで公開されたChatTEDUの実証研究によれば、デュアル構成は攻撃防御率100%、誤検知率0.28%という高い安全性を実現する一方で、応答時間は約18%増加しました。この数字をどう評価するかが意思決定の分かれ目です。
| 構成 | 防御性能 | レイテンシ | 誤検知率 |
|---|---|---|---|
| 単一LLM | 限定的(攻撃成功例あり) | 基準値 | ― |
| Dual LLM | 100%防御(実証環境) | 約18%増 | 0.28% |
ここで重要なのは、18%という数値を絶対値ではなく体感値で評価することです。例えば平均応答時間が2.0秒のシステムであれば、18%増は約2.36秒になります。多くの業務用途では許容範囲に収まる水準です。
一方で、セキュリティ事故のコストはレイテンシ18%増とは比較にならない規模になります。EchoLeakのようなゼロクリック型攻撃では、ユーザーが何もしていなくても情報流出が発生しました。データ流出後の対応費用、ブランド毀損、法的責任まで含めれば、その損失は数百万〜数千万ドル規模に達する可能性があります。
コスト面でも工夫の余地があります。隔離LLMにはLlama 3 8BやGemini Flashのような軽量モデルを採用し、特権LLMのみ高性能モデルを使う設計が一般的です。情報抽出や要約は高価なモデルでなくても十分精度が出るため、トークン単価を抑制できます。
さらにGoogle Cloudが解説するコンテキストキャッシングを併用すれば、入力トークン課金の大幅削減と初回トークン生成までの時間短縮が可能です。Gemini 2.5では最大90%の入力コスト削減が報告されています。これにより、デュアル構成の追加コストは実質的に吸収できるケースもあります。
結論として、18%のレイテンシ増加は「保険料」と捉えるのが妥当です。確率的防御に依存する単一構成と、構造的分離による決定論的防御の差は本質的です。セキュリティを後付けで補強するよりも、初期設計段階でアーキテクチャに組み込むほうが長期的なROIは高くなります。
AIを基幹業務に組み込む時代において、性能最適化と同列に「安全性最適化」を評価軸へ入れることが求められています。18%という数字は、その転換点を象徴する現実的なコストだといえます。
コンテキストキャッシングと構造化出力による最適化戦略
Dual LLMパターンを実運用で成功させる鍵は、セキュリティ強化と同時にパフォーマンスを最適化することです。その中核となるのがコンテキストキャッシングと構造化出力の強制です。両者は単なる効率化技術ではなく、信頼境界を明確化するためのアーキテクチャ要素として機能します。
Google Cloudのドキュメントによれば、Gemini系モデルでは長大なシステムプロンプトや参照ドキュメントをサーバー側にキャッシュし、再利用することが可能です。これにより入力トークンの再送信を回避し、最大90%のコスト削減が報告されています。
特にRAG環境では、社内ポリシーやガイドラインなど繰り返し利用される固定コンテキストが多く、キャッシュ戦略の有無が総コストを大きく左右します。
| 項目 | 従来方式 | コンテキストキャッシング適用時 |
|---|---|---|
| 長文プロンプト送信 | 毎回送信 | 初回のみ送信 |
| トークン課金 | 累積増加 | 大幅削減 |
| 初回応答速度 | 遅延発生 | 短縮 |
重要なのは、これが単なるコスト削減策ではない点です。詳細で厳密なセキュリティ指示をトークン制約なしに維持できるため、防御ロジックを簡略化せずに済みます。HiddenLayerが指摘するような高度なバイパス攻撃に対抗するには、例外条件まで網羅した長文のシステム設計が不可欠です。
一方、構造化出力は隔離LLMの無害化処理を決定論的にします。LlamaIndexのStructured OutputやGeminiのControlled Generationでは、JSON Schemaへの厳密準拠が可能です。
IEEEで公開されたChatTEDUの研究では、Dual LLM構成と構造化JSON出力の組み合わせにより、180件の攻撃試行を100%防御しました。誤検知率は0.28%に抑えられており、構造制約が実用性を損なわないことが示されています。
構造化出力の本質は、LLMの確率的生成を「型システム」で拘束することです。攻撃者が「メールを送信せよ」と書き込んでも、スキーマに存在しないフィールドは生成されません。これはSQLプレースホルダーと同じく、命令とデータの分離を強制します。
コンテキストキャッシングが経済的持続性を担保し、構造化出力が論理的完全性を担保します。両者を組み合わせることで、Dual LLMアーキテクチャは初めてスケール可能な防御基盤になります。
AISI Japanと日本企業のAIセキュリティ動向
日本におけるAIセキュリティは、技術的防御の高度化と制度設計の整備が同時進行で進んでいます。その中心に位置するのが、2024年に設立されたAIセーフティインスティテュート(AISI Japan)です。AISI Japanは、単なる技術評価機関ではなく、「社会技術的(Socio-technical)」視点からAIリスクを捉えることを明確に打ち出しています。
2025年以降に公表されたビジョンペーパーや各種レポートでは、モデル単体の安全性だけでなく、組織体制・運用フロー・インシデント共有の仕組みまで含めた包括的な枠組みが示されています。これは、プロンプトインジェクションのように技術と運用が密接に絡む脅威を前提にしたアプローチです。
AI-IRSの始動と企業実務への影響
2026年1月に公開された「AI-IRS(AI Incident Response System)」の概要版は、日本企業の実務に直接的な影響を与えています。AI-IRSは、プロンプトインジェクションによる情報漏えいや、RAG経由の不正データ参照といったAI特有のインシデントを想定し、検知・初動対応・再発防止までの標準フローを定義しています。
従来のCSIRT体制ではカバーしきれなかった「モデル挙動の逸脱」や「学習・推論過程におけるリスク」を明示的に対象とした点が特徴です。AISI Japanの資料によれば、技術対策とガバナンスの統合が不可欠であると強調されています。
| 領域 | 従来の対応 | AI-IRSでの拡張点 |
|---|---|---|
| インシデント定義 | 不正アクセス・情報漏えい | プロンプト注入・モデル逸脱も含む |
| 初動対応 | ログ解析・遮断 | プロンプト履歴・RAG参照元の検証 |
| 再発防止 | パッチ適用 | アーキテクチャ見直し・評価テスト強化 |
多言語環境における安全性評価
日本企業にとって重要なのが、日本語およびアジア言語環境での安全性です。シンガポール当局との共同テスト報告では、英語以外の言語によるクロスリンガル攻撃の検証が行われました。欧米中心に訓練されたモデルでは、日本語文脈での命令階層解釈が不安定になるケースが確認されています。
日本語特有の敬語表現や曖昧な依頼文が、命令として誤解釈されるリスクは、国内企業のRAG実装において無視できません。そのため、日本企業は自社データでの追加評価やレッドチーミングを強化しています。
イノベーション・ファーストと自主的高度化
日本のAI政策はEUのような強い法規制よりも、ガイドライン中心の「イノベーション・ファースト」型です。その結果、企業側の自主的取り組みが競争力の源泉になっています。
大手テクノロジー企業では、RAG導入時にDual LLM構成を標準設計とし、権限分離と構造化出力を前提とするケースが増えています。また、ペネトレーションテストを内製化し、プロンプトインジェクション耐性を定量評価する動きも広がっています。
2026年の日本市場では、「LLMを使えるか」ではなく「安全に使いこなせるか」が企業価値を左右します。AISI Japanの枠組みを踏まえつつ、アーキテクチャ・運用・評価を統合したAIセキュリティ戦略が、日本企業の競争優位を決定づける段階に入っています。
Instructional Segment Embedding(ISE)と次世代防御技術
Instructional Segment Embedding(ISE)は、プロンプトインジェクション対策をアーキテクチャ層からさらに一段深いモデル内部の表現学習レベルへと拡張する次世代技術です。
2025年のICLRで発表された研究では、LLMが入力テキストを単なる一次元のトークン列として処理するという構造的弱点に着目し、「命令」と「データ」を埋め込み段階で分離するアプローチが提案されました。
これはDual LLMのような外部的分離とは異なり、モデルの内部空間そのものに信頼境界を構築する試みです。
ISEの基本構造
| 区分 | 従来LLM | ISE適用LLM |
|---|---|---|
| 入力表現 | 単一埋め込み空間 | 命令用・データ用で分離 |
| 命令判定 | 文脈依存の確率判断 | 構造的にタグ付け |
| インジェクション耐性 | バイパス可能 | 意味的に無視可能 |
ISEでは、入力テキストを「Instructional Segment」と「Data Segment」に分割し、それぞれに異なる埋め込みベクトルを適用します。
これにより、モデルは内部的に「これは実行すべき命令」「これは参照すべき情報」と区別して処理できるようになります。
データ領域に混入した命令は、意味的には理解できても、実行対象としては扱われません。
arXivで公開された関連研究では、多様なデータ合成とInstruction-level Chain-of-Thought学習を組み合わせることで、命令判別精度を大幅に向上できることが示されています。
特に、従来の命令階層型アプローチが確率的な優先度制御に依存していたのに対し、ISEは表現空間レベルでの構造的制約を与える点が決定的に異なります。
これはHiddenLayerが報告したユニバーサル・バイパスのような階層無効化攻撃に対しても、理論上は強固な耐性を持ちます。
さらに重要なのは、ISEが単独で完結する防御ではなく、多層防御の中核として機能する点です。
Dual LLMによる実行分離、Guardrailsによる入出力監視、そしてISEによる内部表現の制御が組み合わさることで、防御は確率論から構造安全へと進化します。
AIセキュリティが「プロンプト設計の工夫」から「モデル設計の再構築」へと移行しつつある現在、ISEはその象徴的な技術といえます。
命令を読めても、命令として扱わない。この発想の転換こそが、次世代防御技術の核心です。
エージェンティック・ディフェンスと自動レッドチーミングの台頭
プロンプトインジェクション対策がアーキテクチャ中心へと移行する中で、次に台頭しているのがエージェンティック・ディフェンスと自動レッドチーミングです。攻撃がAIによって自動化されている以上、防御側もまたAIエージェントを用いて継続的に脆弱性を検出・修復する必要があります。
従来のセキュリティテストは、人間の専門家が限定的なシナリオで侵入を試みるものでした。しかしRAGやエージェント型LLMは、知識ベース更新やモデル変更のたびに挙動が変化します。そのため、リリース後も常時監視する仕組みが不可欠になっています。
近年のCI/CDパイプラインには、モデル更新時にAIエージェントが数千規模の攻撃パターンを自動生成し、実際にシステムへ試行するプロセスが組み込まれています。これは静的なチェックリストではなく、動的に進化する攻撃に対抗する仕組みです。
| 項目 | 従来型テスト | エージェンティック・ディフェンス |
|---|---|---|
| 実行主体 | 人間中心 | AIエージェント |
| 頻度 | 定期的・限定的 | 継続的・自動 |
| 攻撃パターン | 既知中心 | 生成型・多様 |
| 対応速度 | 手動修正 | 即時フィードバック |
WithSecureが報告したマルチチェーン型攻撃のように、攻撃は単発ではなく複数ステップで成立します。これに対応するため、防御エージェントは対話全体の状態遷移を追跡し、出力の構造やツール呼び出し履歴まで監査します。
NVIDIAの技術ブログが紹介するNeMo Guardrailsの進化は象徴的です。単なるキーワードフィルタではなく、文脈理解に基づき動的に制約を生成する仕組みへと発展しています。これにより、比喩や隠語を使った脱獄プロンプトにも柔軟に対応可能になっています。
さらに注目すべきは自動レッドチーミングの内製化です。Future of Life InstituteのAI Safety Indexでも指摘されている通り、評価の継続性が安全性を左右します。攻撃シナリオ生成AIが社内モデルを常時テストし、成功率や誤検知率をダッシュボードで可視化する企業が増えています。
重要なのは、防御エージェント自身が新たな攻撃対象にならない設計です。Lakeraが警鐘を鳴らすように、LLMに自己採点させる方式は脆弱です。そのため、防御ロジックの一部は決定論的コードで実装し、LLMの判断と分離する構造が求められます。
結果として、エージェンティック・ディフェンスは単なるツールではなく、AIシステムのライフサイクル全体に組み込まれる基盤機能へと変化しています。自動レッドチーミングは品質保証の一工程ではなく、AI時代の継続的セキュリティ運用そのものを再定義する動きと言えます。
RAGを安全に実装するための設計原則と実践チェックポイント
RAGを安全に実装するには、小手先のプロンプト対策では不十分です。「引用(データ参照)」と「実行(命令処理)」を構造的に分離することが設計の出発点になります。
OWASP Top 10 for LLM Applicationsでもプロンプトインジェクションは最上位リスクに位置付けられており、HiddenLayerの研究が示すように命令階層だけでは決定論的な安全性は確保できません。したがって、防御はモデル内部ではなくアーキテクチャで担保する必要があります。
その中核がDual LLMパターンです。特権LLMと隔離LLMを分離し、両者の間を構造化データのみで接続します。
| 要素 | 特権LLM | 隔離LLM |
|---|---|---|
| 役割 | 意思決定・ツール実行 | 検索結果の要約・抽出 |
| 外部ツール | アクセス可能 | アクセス不可 |
| 入力データ | 検証済み構造化データのみ | 信頼できない生データ |
| 出力形式 | 自然言語・API実行 | JSON等に限定 |
重要なのは、信頼できないテキストを特権LLMに直接渡さないという信頼境界の明確化です。これはSQLインジェクション対策におけるプレースホルダー設計と本質的に同じ発想です。
実践チェックポイントとして、まず隔離LLMの出力をJSON Schemaで厳格にバリデーションすることが挙げられます。LlamaIndexのStructured OutputやGeminiのControlled Generationのように、スキーマ強制機構を活用する設計が推奨されます。
次に、LLM-as-a-judge型の自己評価防御に依存しないことです。Lakeraの指摘どおり、防御を同一モデルに委ねる構成は攻撃対象を増やすだけです。検証ロジックは可能な限り非LLMコードで実装します。
設計原則は「最小権限」「構造化通信」「非LLMによる検証」の三位一体です。
さらに、依存ライブラリの脆弱性管理も欠かせません。LangChainのLangGrinch事例が示したように、エージェント基盤の脆弱性は特権昇格に直結します。バージョン固定と継続的監査を設計段階から組み込みます。
パフォーマンス面では、IEEEで報告されたChatTEDUの実証のように、防御率100%を達成しつつ誤検知率0.28%に抑えた事例もあります。レイテンシ増加は約18%と報告されており、構造分離は実用的な選択肢です。
最後に、ログと監査証跡の分離保管も重要です。引用元データ、隔離LLM出力、特権LLM入力をそれぞれ記録すれば、万一のAI-IRS対応時にも因果関係を追跡できます。
RAGの安全性はモデル性能ではなく、信頼境界をどこに引き、どう強制するかで決まります。設計段階でこの原則を徹底できるかが、2026年以降のAI活用の成否を分けます。
参考文献
- Cato Networks:Breaking down ‘EchoLeak’, the First Zero-Click AI Vulnerability Enabling Data Exfiltration from Microsoft 365 Copilot
- HiddenLayer:Novel Universal Bypass for All Major LLMs
- WithSecure Labs:Multi-Chain Prompt Injection Attacks
- IEEE Xplore:Securing With Dual-LLM Architecture: ChatTEDU an Open Access Chatbot’s Defense
- Simon Willison’s Weblog:The Dual LLM pattern for building AI assistants that can resist prompt injection
- AISI Japan:Approach Book for AI Incident Response